不重復抓取?有很多初學者可能會覺得。爬蟲不是有深度優先和廣度優先兩種抓取策略嗎?你這怎麼又多出來一個不重復抓取策略呢?其實我這幾天有不止一次聽到了有人說要在不同頁面增加同一頁面鏈接,才能保證收錄。我想真能保證嗎?涉及收錄問題的不止是抓沒抓吧?也從而延伸出今天的這篇文章,不重復抓取策略,以說明在一定時間內的爬蟲抓取是有這樣規則的,當然還有很多其他的規則策略,以後有機會再說,例如優先抓取策略、網頁重訪策略等等。
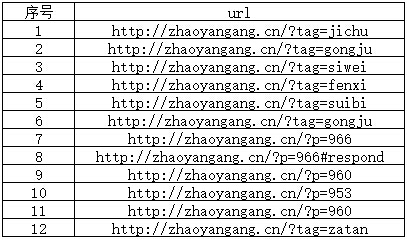
回歸正題,不重復抓取,就需要去判斷是否重復。那麼就需要記住之前的抓取行為,我們舉一個簡單的例子。你在我的QQ群(9060800)裡看到我發了一個URL鏈接,然後你是先看到了我發的這個鏈接,然後才會點擊並在浏覽器打開看到具體內容。這個等於爬蟲看到了後才會進行抓取。那怎麼記錄呢?我們下面看一張圖:
如上圖,假設這是一個網頁上所有的鏈接,當爬蟲爬取這個頁面的鏈接時就全部發現了。當然爬取(理解為發現鏈接)與抓取(理解為抓取網頁)是同步進行的。一個發現了就告訴了另外一個,然後前面的繼續爬,後面的繼續抓。抓取完了就存起來,並標記上,如上圖,我們發現第2條記錄和第6條記錄是重復的。那麼當爬蟲抓取第二條後,又爬取到了第6條就發現這條信息已經抓取過了,那麼就不再抓取了。爬蟲不是盡可能抓更多的東西嗎?為什麼還要判斷重復的呢?
其實,我們可以想一下。互聯網有多少網站又有多少網頁呢?趙彥剛是真沒查證過,但這個量級應該大的驚人了。而本身搜索引擎的爬取和抓取都是需要執行一段代碼或一個函數。執行一次就代表著要耗費一丁點資源。如果抓取的重復量級達到百億級別又會讓爬蟲做多少的無用功?耗費搜索引擎多大的成本?這成本就是錢,降低成本就是減少支出。當然不重復抓取不光體現在這裡,但這個是最顯而易見的。你要知道的就是類似於內容詳情頁的熱門推薦、相關文章、隨機推薦、最新文章的重復度有多大?是不是所有頁面都一樣?如果都一樣,那麼可以適當調整下,在不影響網站本身的用戶體驗前提下,去適當做一些調整。畢竟網站是給用戶看的,搜索引擎只是獲取流量的一個重要入口,一種營銷較為重要的途徑!
- 上一頁:分析一下百度競價好還是SEO優化好呢
- 下一頁:百度SEO網站排名分析