百度不收錄網站的原因我大致分為內容問題、結構設計問題以及其他問題。網站不被收錄,我們就無法將網站的信息更好的傳達給我們的目標受眾;下面我將圍繞前面提到的三個問題闡述下百度不收錄的原因,並糾正一些其他的個人認為概念上的錯誤問題:
1.新站處於百度考核期
看到有些人表達的觀點是新站處於百度考核期可能會不被收錄,我對這種觀點表示不贊成,只要是新站,新域名,在結構以及內容上面如果不是高度重復的話,一般都會被收錄,至於所說的百度考核期,我們表示不認同。百度考核期應該是在網站首頁被收錄後,不收錄其他頁面時該考慮的問題。
2.您網站的robots協議禁止百度抓取
每個網站都有一個robots.txt,搜索引擎來的網站的時候,會先查看這個文件,百度蜘蛛與google機器人不同之處也在於此,當google機器人去爬網站,發現robots設置了禁止蜘蛛的抓取時,蜘蛛就會退出,不抓取任何網站內容;而百度對設置robots的生效時間不是即使的,所以當您設置好robots時,可能您的網站已經被百度收錄(可能由於您提交至搜索引擎或者是發布過導入鏈接),所以robots協議禁止百度抓取而導致不收錄的幾率是非常的小。
3.網站內容有敏感語言
百度被央視曝光了以後,對抓取內容可能會更加規范。對於一些帶有敏感性話題的內容,會不進行抓取,這個也是造成不收錄。雖說個人站長可能在發布文章時不會帶此言語,但是我們不能確定給我們留言評論的內容是否帶有這些敏感內容,我們不能確定網站是否被入侵,在網站內部生成了一些敏感性的頁面內容。所以,在留言評論方面,我們要做好嚴格的審核機制,要定期做網站內部文件進行整理。
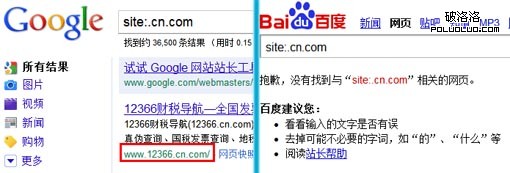
4.其他問題
目前遇到一種情況就是後綴名為.cn.com的域名在百度暫時不被收錄,而在google收錄良好,具體原因還不清楚。
5.網站是復制自互聯網上的高度重復性的內容
當然,不僅是百度,其他搜索引擎一樣反對高度重復性內容,所以,要想運營網站,內容也是必要的保證,完全靠復制內容的網站是無法再搜索引擎生存的。
6.網站在設計或者結構上存在缺陷,導致蜘蛛無法正常抓取
很多網頁設計公司的程序員並不懂SEO,他們會將網站設計得很精美,也許是全站FLASH,也許是網站框架結構(iframe),也許網站是由javascript或者ajax拼裝起來的,也許是圖片太多,文本太少,這些百度蜘蛛爬起來是非常的費勁,甚至直接不抓取,百度SEO指南已證實了這一點。
7.網站不被百度收錄且都不符合以上內容,那麼,我們需要查看網站日志進一步了解原因
如果百度蜘蛛抓取網頁返回的是200 0 0代碼,則表示該網頁已經成功編進索引;若返回的是200 0 64則表示該索引數據庫已經存在,沒有發現網頁有更新的內容,不需要重新索引。
假如沒有蜘蛛來爬行抓取過,那我們就再提交一次網址,並保持網站內容的定期更新(純原創或者高度偽原創),同時增加外鏈(包括友鏈、簽名鏈等高質量的外部鏈接)相信不久的幾天,您的網站即將被收錄。