企業的多渠道整合架構及統一數據模型需求
隨著企業業務的增長,企業的系統也在不斷增長中。這些系統有的是提供給內部用戶使用,有的是為外部客戶使用,通過多種渠道訪問企業的業務,形成了如下架構圖中的多渠道的企業架構。如銀行的多渠道架構,客戶可以通過浏覽器的網上銀行,手機銀行,高櫃,低櫃台,電話銀行,ATM 服務等等來進行銀行業務辦理。
圖 1. 企業前端渠道應用的特點 – 多渠道、以客戶為中心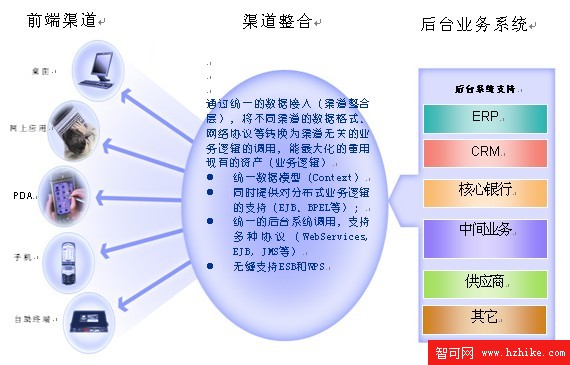
查看原圖(大圖)
在企業的業務系統增長中,由於不同的業務系統構建時間不一樣,業務目標側重點也不一樣,更重要的是企業沒有站在企業架構的層次來統一的考慮供多渠道的企業的統一數據字典,使得企業的各個業務系統中數字字典混亂,甚至互相沖突。這造成了諸多的弊端,如:
不同業務系統重復定義數字字典,不便於重用,並增加開發部門的開發工作量
沒有統一的數據字典,不便於後期統一維護(修改,更新,刪除)。
沒有統一的數據字典,不便於數據集成。如客戶在銀行網點已經填寫了一系列的客戶信息,當過幾天去申請信用卡的時候,用戶被同樣的要求輸入幾天前剛提供的信息。給終端用戶也造成了諸多不便。
沒有統一的數據字典,造成不同的業務系統的數據規范不同意,如向同一個用戶在不同的業務系統中要相同的數據。如客戶在某銀行申請了儲蓄卡賬號,被要求輸入了一系列的客戶信息,其中包括職業一項。當該用戶信用卡申請表單中也被要求輸入一些列信息,也包括職業一欄目。但是這兩項的填寫選項,輸入格式完全不一樣。造成了同樣的信息在不同的業務系統中規范完全不統一的問題。
企業需要一個通用的數據字典在企業架構層次被所有的業務系統所重用。本文介紹的基於 XML 的數字字典方案—— Context 數字字典可以為企業的多渠道系統提供統一的數據字典,包括類型定義,數據結構定義,校驗規則,轉換規則等。基於 XML 的統一數據字典,解決了上面的所有缺點。另外還提供了下面這些優點:
基於 XML 語言,支持多平台、多渠道,容易被各個業務系統所重用。
學習曲線快,不懂技術的業務人員也可以編輯企業數字字典。對高級技能程序員的依賴減少。本案在土耳其有個客戶,利用 Context 數據字典工具,聘請了一些高中生就可以使用工具進行開發。
縮短開發周期。XML 簡單易讀,可以手工編輯或者借助一些 XML 編輯工具快速編輯。
便於格式轉換,容易與第三方或合作伙伴企業之間進行通訊和業務調用。
根據上面的分析,我們知道企業多渠道 統一數據字典能夠解決企業當前碰到的一些問題,具備商業可行性。接下來的篇幅將介紹 Context 數據字典的架構、設計、以及應用實例。
統一數據模型的架構
企業統一的基於 XML 的 Context 數據模型是構建在上下文 (Context) 基礎上的。Context 是針對某一上下文操作定義的包含企業數據和服務的對象。不同的 Context 可以通過父子鏈接組成一個 Context 樹。
圖 2. Context 樹狀結構實例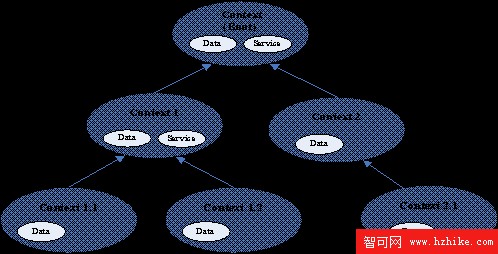
基於 XML 的 Context 統一數據模型在架構設計上具有以下特性:
支持數據的層次化存取
Context 數據模型最為獨特的特性就是通過 Context 樹支持數據的層次化。在 Context 樹裡不同層次的 Context 存放著不同層次和級別的數據和服務。每個子 Context 可以訪問它的父 Context 和祖先 Context 的數據和服務。同時通過根上下文(Root Context)可以對整個 Context 樹進行遍歷和管理。
完全基於 XML 的統一定義和工具支持
在 Context 數據字典裡,Context 樹的定義,包括 Context 裡包含的數據和服務的定義,以及數據類型的定義,都是完全基於 XML 的。 同時有一系列工具支持數據字典的創建和編輯。這一切都大大提高了數據字典的開發和維護效率。
支持企業業務數據共享
通過 Context tree, 父 Context 的數據可以被子 Context 所共享。比如,對於企業服務端的多渠道應用,一些跨渠道的共享數據可以放在 root context 中被各渠道不同交易的 Context 所共享。再比如,對於網上銀行的應用,每個登錄用戶的用戶信息可以放到每個用戶單獨的 session context 中,此 session context 被此用戶執行的不同交易的 context 共享。
統一的數據訪問接口
Context 數據字典提供了對外的統一的訪問接口,不同的數據類型和持久化模式的數據都可以通過統一的接口進行操作。
支持數據持久化
Context 數據模型按是否支持持久化可以分為 Local Context 和 remote context。Local Context 不能被持久化且只能在同一個 JVM 裡被訪問和共享。Remote Context 可以被持久化到數據庫中,並可以被跨 JVM 訪問。
多平台、可擴展
Context 數據字典的底層實現是基於 java 的,因此也具有跨平台的可移植性。同時 Context 數據字典的數據項和類型都支持被用戶擴展, 平且用戶可以設定自定義的數據校驗器和轉換器。
統一數據模型的元素
數據類型 Type 定義
企業數據類型可包含 Type 類型和 Generic 類型。Type 數據元素代表業務對象,如日期(Date)、帳戶列表(AccountList)、金額(Money)。它與非 Type 數據元素的主要區別是:Type 數據包含業務類型和業務規則信息,其中業務規則信息可包括數據顯示格式、數據值域等等。Type 包含一個或者多個 Property Descriptors 來存儲業務規則信息,而非 Type 類型則沒有。一個典型的 Type 定義如下:
清單 1. 典型類型定義實例
<type id="Money" implClass="com.ibm.btt.base.DataFIEld">
<Descriptor id="typeDefault"
implClass="com.ibm.btt.base.types.ext.FloatDescriptor">
<Converter convTypes="default"
implClass="com.ibm.btt.base.types.ext.FloatConverter"/>
<Validator implClass="com.ibm.btt.base.types.ext.FloatValidator"
lowerLimit="0"/>
</Descriptor >
</type>
Money 使用 Validator 確保了它的最小值為 0,Converter 將數據元素轉化為字符串(String)類型。
現實世界中的數據分為兩類:簡單型和復合型。姓名(Name)屬於一個簡單型,而個人信息 { 姓名,住址,資產 } 則屬於復合型。 同理 Type 也分為 Simple 型和 Compound 型,Simple Type 僅包含一個 Property Descriptor,或者說該 Type 僅由一個 Property Descriptor 描述。Compound Type 含有多個 Property Descriptor:一個默認的 Property Descriptor,多個指向其他子 Type 的 Property Descriptor。
清單 2. 帶有校驗的類型定義實例
<type id="String" implClass="com.ibm.btt.base.DataFIEld">
<descriptor id="typeDefault"
implClass="com.ibm.btt.base.types.ext.StringPropertyDescriptor">
<Converter convTypes="default,host"
implClass="com.ibm.btt.base.types.ext.StringConverter"/>
<Validator implClass="com.ibm.btt.base.types.ext.StringValidator"/>
</descriptor>
</type>
<type id="PersonInfo" implClass="com.ibm.btt.base.KeyedCollection">
<descriptor id="typeDefault"
implClass="com.ibm.btt.base.types.KCollPropertyDescriptor"/>
<dataDescriptor id="name" refType="String"/>
<dataDescriptor id="address" refType="String"/>
<dataDescriptor id="asset" refType="Money"/>
</type>
用戶可以通過如下方法使用 PersonInfo 數據類型:
清單 3. 使用 PersonInfo 數據類型實例
KeyedCollection info = (KeyedCollection)DSEType.readObject("PersonInfo");
info.setValueAt("name", "Tom");
info.setValueAt("address", "ZhongShan Road, Xian");
info.setValueAt("asset", new Float(5000));
數據及復雜數據項 Data 定義
統一企業數據模型中使用 XML 描述數據字典,XML 的層次結構與現實世界數據對象結構天衣無縫的映射。用戶無需做概念抽象,可以非常簡單實現從設計到代碼的轉換。為了適應現實中的層次數據結構,統一數據模型引入組合設計模式(Composite Pattern)描述數據對象關系。如圖所示:
圖 3. 數據類型層次圖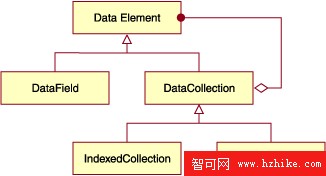
數據模型的最頂端為抽象類 Data Element,它定義了數據元素或者集合類的共有信息 ID 和描述信息。一個數據元素可以是單值或者是集合,這在最大程度上實現了代碼重用。DataField 是統一數據模型中唯一可賦值的單元數據,在內存中每個 FIEld 包含一個值(Value)實例用來存儲數據值。DataFIEld 定義示例如下:
<field id="fIEld1" description="This is an example"/>
Keyed Collection 是一個有序的數據集合,使用數據名稱來訪問其中的數據元素,
所以出現在同一個 Keyed Collection 的數據名稱必須唯一。可以簡單的把 Keyed Collection
想象為字典(Dictionary),內部的數據元素被組織為鍵值對(Key-value pairs),如下所示:
<kColl id="coll1">
<field id="fIEld1"/>
<field id="fIEld2"/>
</kColl>
Indexed Collection 類似數組,使用位置(Position)訪問其內部元素,
所有內部元素為同一種類型。如圖所示。如需訪問 customer 中的街道信息,
可以使用組合鍵:
customerListData.2.address.street。
圖 4. 復雜數據類型實例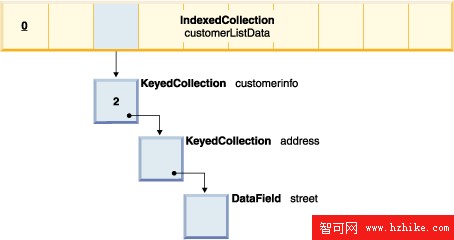
若很多個數據元素均包含一些相同數據元素,為了避免重復代碼,使用引用標簽代替這些重復定義。
清單 4. 引用標簽實例
<kColl id="coll1">
<field id="fIEld1"/>
<field id="fIEld2"/>
</kColl>
<iColl id="icoll1" size="2">
<refData refId="coll1"/>
</iColl>
數據結構 Context 定義
Context 定義了一個操作或者業務實體的資源集合(數據和服務)。Context 作為基本資源模型將應用系統中各 Operation 松散的耦合在一起,Operation 交互只需要將 Context 中數據格式化後雙向傳遞。
Context 被組織成為樹狀結構,頂層是通用資源,底層為專用資源。Context 樹在系統中有且只有一個,因此所有的用戶操作可以共享 Context 樹中的資源。例如,一個用戶 Context 包含用戶級信息,同時它含有幾個子 Context,分別包含一些操作信息。Context 采用職責鏈模式,當 Operation 請求一些數據或者服務時,但在當前的 Operation Context 中無法找到這些資源信息,會自動從 Parent context 中查找,直到找到資源為止。一個典型的 Context 定義如下所示:
清單 5. Context 定義實例
<context id="myWorkstation" type="workstation" parent="myBranch">
<refKColl refId="myWorkstationData" />
<refService refId="msreService" type="service" alias="msre"/>
</context>
如前所述,Context 為所有 Operation 所共享,當位於多個線程中 Operation 同時訪問同一個資源時,系統會自動將訪問所有 Context Tree 上的請求串行化,這樣可以確保資源(數據)訪問的有效性和正確性。
程序是由算法和數據構成,算法在執行的過程中會用到其他輔助的服務資源,例如記錄日志,訪問數據庫,連接服務器等服務資源。在統一企業數據模型中,將算法定義為 Operation,
數據和資源均被定義在 Context 中,而 Context 中包含數據(Data)和輔助資源(Service)。如前所述,Context 采用職責鏈模式,設計 Context 層次結構時需按照物理意義指明每個 Context 的責任。例如,在銀行櫃員(Teller)系統中,如果某個數據是被在同一支行(Branch)服務器所管轄的所有工作占共享,那麼將該數據定義在支行層次(branch-level)的 Context 中。若工作站 Context (Workstation Context)是 Branch Context 的孩子,那麼 Branch Context 的資源對於 WorkStation Context 是可見的。在 Context 內部每個資源都有一個名字,但在 Context 樹中可以存在相同名字的資源,訪問 Context 內部資源時,由底至上找到第一個同名的資源即可。
企業統一數據模型實例
在這裡介紹使用 Context 數據模型實現多渠道銀行應用的一個實例。此銀行實現櫃員桌面富客戶端和網上銀行的多渠道整合,並重用服務端的業務邏輯如賬戶查詢、轉賬等。在這裡假設富客戶端通過 Java ClIEnt 渠道,網上銀行通過 Html ClIEnt 渠道接入服務端。在服務端我們定義 Context 數據模型如下:
圖 5. 服務器端的 Context 樹狀結構實例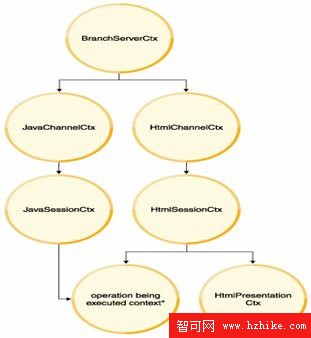
這裡 BranchServerCtx 被定義為 Root Context, 它包含跨渠道的數據和服務, 如後端連接,日志服務等。Java Channel Context 和 Html Channel Context 被定義為 BranchServerCtx 的子 Context, 它們包含渠道連接特性的數據如客戶端類型數據。在各自渠道 Context 下,分別下掛 Session Context。它們包含的是和用戶會話相關的共用數據,如客戶信息,賬戶信息等。在通過各渠道執行交易的時候,系統在運行時動態創建交易操作的 Operation Context, 並鏈接到 Session Context 上。各交易的 Operation Context 如 AccountQueryCtx 和 TransferCtx 都能共享 Session Context 的數據。並通過 Session Context 共享 Channel Context 和 BranchServerCtx 的數據。
首先定義的是 branchServer Context,它是 Root Context,它包含共享的銀行數據和服務資源,如下所示:
清單 6. 企業數據字典定義實例
<context id="branchServer" parent="nil" type="branch">
<refKColl refId="branchData"/>
<refService alias="CSServer" refId="realCSServer" type="cs"/>
<refService refId="CommunicationsPool" alias="pool" type="pool"/>
</context>
<kColl id="branchData">
<refData refId="BranchId"/>
</kColl>
// 然後定義渠道上下文 Channel Context, 它是父 Context 是 branchServer Context。
<context id="JavaChannelCtx" parent="branchServer" type="op">
<refKColl refId="JavaChannelData"/>
</context>
<kColl id="JavaChannelData">
<refData refId="clIEntType"/>
</kColl>
// 接下來定義的是渠道會話 Context,它包含用戶登錄後的會話上下文操作所用到的數據如用戶 ID、
客戶信息、賬戶信息等。Session Context 在用戶登錄後會被創建並鏈接為 Channel Context
的子 Context。為了簡潔起見,下面只列出了 Java 渠道的 Session Context 定義。
<context id="JavaSessionCtx" type="op">
<refKColl refId="JavaSessionData"/>
</context>
// 在上面會話上下文包含的是一個集合數據 JavaSessionData, 它被定義為一個
KeyedCollection 如下:
<kColl id="JavaSessionData">
<refData refId="TID"/>
<refData refId="UserId"/>
<refData refId="CustomerId"/>
<refData refId="CustomerName"/>
<refData refId="AccountList "/>
<refData refId="HostBuff"/>
<refData refId="sessionID"/>
</kColl>
// 在其中包含的賬戶信息被定義為一個賬戶類型數據的數組 (Indexed Collection)。
<iColl id="AccountList">
<refData refId="account "/>
</iColl>
<data id="account" refType="Account"/>
// 賬戶類型定義如下:
<type id="Account" implClass="com.ibm.dse.base.KeyedCollection">
<descriptor id="typeDefault"
implClass="com.ibm.dse.base.types.KCollPropertyDescriptor"/>
<dataDescriptor id="Name" refType="String"/>
<dataDescriptor id="Type" refType="String"/>
<dataDescriptor id="AccountNumber" refType="String"/>
<dataDescriptor id="Balance" refType="Amount"/>
</type>
// 最後我們需要針對交易操作定義 Operation Context, 如針對轉賬交易定義
transferOperationCtx。轉賬交易 Context 是 Session Context 的子 Context,
能共享上層鏈路上所有 Context 的數據。
<context id="transferOperationCtx" type="oper">
<refKColl refId="accountTransferData"/>
</context>
<kColl id="accountTransferData">
<data id="acctFrom" refType="String">
<param id="isMandatory" value="true" />
</data>
<data id="acctTo" refType="String">
<param id="isMandatory" value="true" />
</data>
<data id="amount" refType="String">
<param id="isMandatory" value="true" />
</data>
< data id="AccountBalance" refType="Money"/>
<fIEld id="outcome" />
<fIEld id="TrxReplyCode" />
<fIEld id="TrxErrorMessage" />
</kColl>
通過以上的 Context 數據模型定義實例,可以看到對於企業復雜數據結構和類型的支持非常充分,並且各個層次的數據定義在邏輯上很清晰,能很好的支持數據共享,減少數據冗余,並且支持不同業務渠道的數據整合。
總結
隨著企業應用復雜度增加,使用基於 XML 中間語言的統一數據模型能夠降低企業數據字典的建立、維護的復雜性,為企業帶來技術價值和業務價值。
文章作者根據在行業應用框架中間件的工作經驗,抽象和介紹了基於 XML 中間語言的統一數據模型 Context 的架構、組件、設計原理、以及使用實例。
- 上一頁:SMIL 3 領域重點:探索不斷擴展的同步多媒體領域內的開源工具和技術
- 下一頁:使用 WebSphere Message Broker 的 WebSphere Transformation Exte