搜索引擎通過一種程序robot(又稱spider),自動訪問互聯網上的網頁並獲取網頁信息。但是,如果網站的某些信息不想被別人搜索到,可以創建一個純文本文件robots.txt,放在網站根目錄下。這樣,搜索機器人會根據這個文件的內容,來確定哪些是允許搜尋的,哪些是不想被看到的。
有趣的是,這種特性往往用來作為參考資料,猜測網站又有什麼新動向上馬,而不想讓別人知道。例如通過分析Google的robots.txt變化來預測Google將要推出何種服務。
有興趣的讀者可以看一下Google的robots.txt文件,注意到前幾行就有“Disallow: /search”,而結尾新加上了“Disallow: /base/s2”。
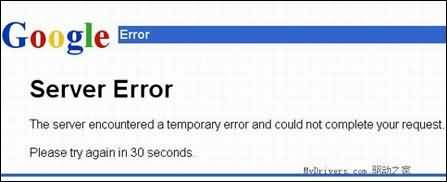
現在來做個測試,按照規則它所隱藏的地址是http://www.Google.com/base/s2,打開之後發現Google給出了一個錯誤提示:“服務器遇到一個暫時性問題不能響應您的請求,請30秒後再試。”
但是把s2最後的數字換成1、3或者別的什麼數字的時候,錯誤提示又是另一個樣子:“我們不知道您為什麼要訪問一個不存在的頁面。”
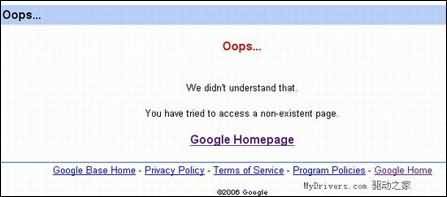
很顯然“/base/s2”是一個特殊的頁面,鑒於Google曾表示過今年的主要焦點是搜索引擎,我們推測一下,所謂的“s2”是否表示“search2”,也就是傳說中的第二代搜索引擎? 1 2 3 下一頁
出於好奇,嘗試了一下百度的robots.txt,比密密麻麻的Google簡潔了許多,只有短短幾行:
User-agent: Baiduspider
Disallow: /baidu
User-agent: *
Disallow: /shifen/dqzd.html
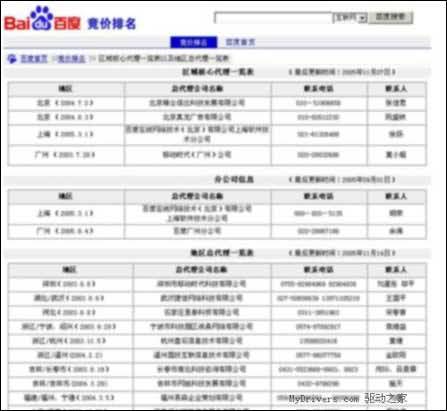
第一段就不用說了,第二段也遇到了同樣打不開的錯誤,不過,按以前的資料來看,這是百度曾經的競價排名的區域核心代理一覽表以及地區總代理一覽表,出於某些可以理解的原因做了模糊處理。
出於好奇,嘗試了一下百度的robots.txt,比密密麻麻的Google簡潔了許多,只有短短幾行:
User-agent: Baiduspider
Disallow: /baidu
User-agent: *
Disallow: /shifen/dqzd.html
第一段就不用說了,第二段也遇到了同樣打不開的錯誤,不過,按以前的資料來看,這是百度曾經的競價排名的區域核心代理一覽表以及地區總代理一覽表,出於某些可以理解的原因做了模糊處理。