本文的 第 1 部分介紹了 XML 的文本和替代表示的一些背景。第 2 部分中我將討論使用不同表示方法的實際性能權衡。這裡的比較並不完善,因為 XML 的表示有很多種不同的選擇,包括針對每種文檔類型的模式生成的二進制表示。但是長期以來關於替代表示方法的爭論多是情緒化的,缺少真正的事實基礎,這些性能比較結果至少可以為希望進行性能比較的開發人員提供一個起點。
度量的標准
比較不同表示的文檔大小很容易,只需要用各種形式寫出同一些數據,然後記錄每種情況的字節數。比較處理速度就稍微麻煩一點。為了公正的比較,必須考察把每種表示轉化成應用程序可用的形式所需要的開銷,以及從應用程序內部數據生成那種表示的開銷。但是,任何特定的應用程序都有自己獨特的內部數據,但是在大量的應用程序中如何選擇才算是公正的呢?
我認為應該使用 XML 文檔的解析事件流表示。因為基本上每個使用 XML 的應用程序都在輸入端使用解析器讀入文檔,並且很多都在輸出文檔中生成等價的解析事件流,這種選擇似乎比較公正。我選用 SAX2 解析器模型作為這些測試的基礎,因為它是目前應用最廣泛的 Java 語言解析器。
測試細節
所有的測試代碼都使用 Java 語言編寫,只要可能就使用標准 Java 組件。測試代碼(可以從 XBIS 站點下載,鏈接參見 參考資料)首先解析每個測試文檔,並把解析生成的事件流保存在內存中。這樣在以後基本上不需要什麼開銷就能回放解析事件流。然後使用保存的解析事件流生成:
文本 XML——通過將其作為 Javax.XML.transform.Transformer 復制轉換的輸入,這是我找到的最快的一種方法;
gzip 壓縮的文本——通過把生成的文本鏈接到 Java.util.zip.GZIPOutputStream ;
或者 XBIS——通過將其作為 org.xbis.SAXToXBISAdapter 的輸入。
我記錄下每種表示的大小,然後反過來把生成的輸出作為輸入來衡量輸入處理的開銷(只需要解析文本形式,對於 gzip 壓縮文本,向解析器鏈接一個 Java.util.zip.GZIPInputStream ,或者將 XBIS 作為 org.xbis.XBISToSAXAdapter 解碼程序的輸入)。每種情況下,已經生成的輸出處理都會生成一個 SAX2 解析事件流,然後對解析事件進行分析,確保原來的文檔內容成功地進行一次來回。
本文中的具體時間度量通過對每個或每組文檔運行 10 遍(讀寫各 5 遍)得到,只記錄最好的那一遍。不是每一遍完成整個來回,而是首先進行輸出生成,然後再測試輸出處理,這樣可以分別測量執行的事件。不同的表示都單獨執行測試程序,以免因為 JVM 的優化造成一組測試對另一組測試產生負面影響。本文中的時間測試在運行 Mandrake Linux 9.1 和 IBM 1.2.1 JVM for Linux 的 Athlon 2000+ 系統上進行。如果用 Sun 1.4.2 JVM 測試,gzip 測試運行的性能要比這裡的結果差很多,輸出處理要多花大約七倍的時間。除了 gzip 測試時間之外,對於其他測試,這兩種 JVM 的結構都差不多。這裡的時間是使用 Piccolo SAX2 解析器得到的,因為它是經過測試的 SAX2 解析器中性能最快的。
測試文檔
我使用了分解成中型和大型獨立文檔的測試數據集,以及一些更小文檔的集合。中型文檔包括:
periodic.xml——XML 形式的元素周期表(114K 字節)
soap.XML——從一個測試 Web 服務中截獲的 SOAP 響應消息(157K 字節)
xml.xml——包含實體定義的 XML 推薦標准文本(156K字節)
大型文檔包括:
weblog.xml——重新格式化為 XML 的 Web 頁面訪問日志(2.9M 字節)
factbook.xml——重新格式化為 XML 的 CIA World Factbook 數據(4.0M 字節)
小型文檔集合包括:
ants——Ant 構建工具使用的 XML 配置文件(18 個文件,共 100K 字節)
fms——來自 Freshmeat.Net 的 RDF 文檔(37 個文檔,共 136K 字節)
soaps——示例 SOAP 文檔(42 個文檔,共 30K 字節)
webs——Web 應用程序配置文件(70 個文檔,共 132K 字節
看看結果吧
圖 1 到圖 3 給出了實際的測試結果。總的輸出大小以 gzip 最小(文本是 8.0 MB,gzip 是 1.3 MB,XBIS 是 4.1 MB),平均壓縮比超過 6:1,但 gzip 的處理時間也是最長的。gzip 格式的處理開銷主要在輸出端,輸入端基本上和普通文本一樣快。但是 gzip 的輸出時間要比輸入時間大得多,gzip 代碼總的運行速度大約是文本的三分之一。
圖 1. 中型文檔的測試結果
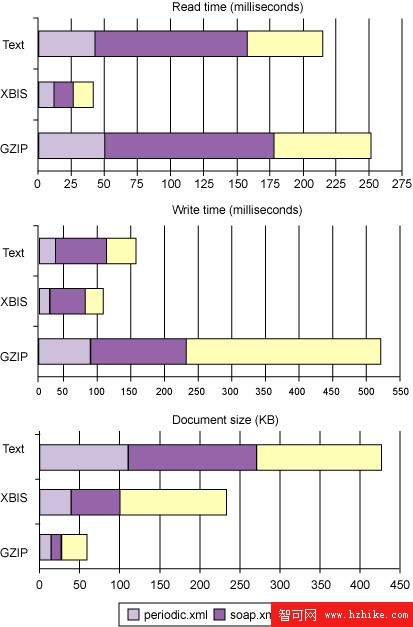
對於各種大小和類型的測試文檔,XBIS 的性能最好,總體速度比文本快兩倍,比 gzip 快六倍。對文本的壓縮相對較小,為 2:1,但仍然大大降低了帶寬需求。
圖 2. 大型文檔的測試結果
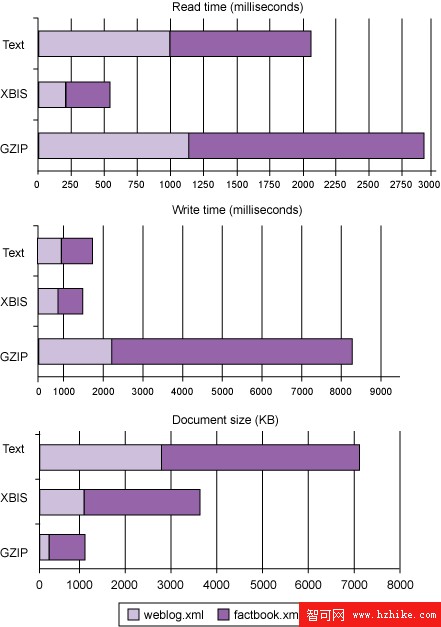
圖 3 中對小型文檔集合的測試結果表明,gzip 對較大文檔的壓縮要比小型文檔好得多。每組中的每個文檔都使用 gzip 單獨壓縮,因為文檔需要保持獨立(多個文檔可以使用 XML 在一個流中一起處理,因為文檔間沒有明確的界限)。圖 3 中文檔集合的整體大小相對較小,因此 gzip 編碼的低效性對整體結果影響不大。
圖 3. 小型文檔集合的測試結果
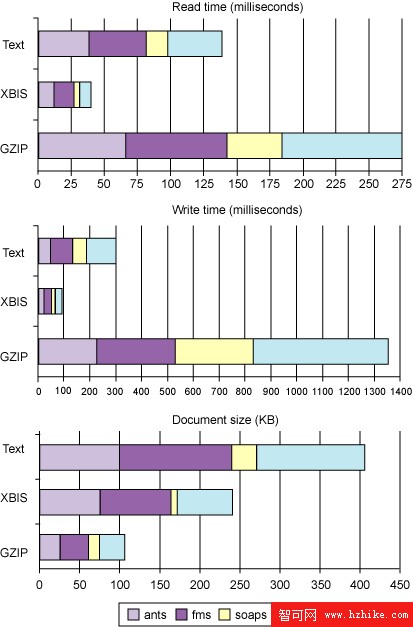
使用 gzip 的 XML 感知版本有可能改善 gzip 的時間測量結果。這樣就不需要在 gzip 的輸入和輸出中都經過一個額外的步驟(XML 文本)。gzip 的 XML 感知版本也可以結合其他技術如 XMill(請參閱 參考資料)的思想。盡管 gzip 不大可能趕上 XBIS 的速度。
XBIS 的優點
XBIS 能獲得較好的處理速度是因為它具有文本 XML 處理所沒有的幾種不同的優點。一個優點是消除了 XML 文本的很多冗余。減少冗余可以使表示更短,也是它處理起來更快(特別是對於輸入)。另一個優點是和文本 XML 解析器支持的多種不同編碼相反,只使用一種方法編碼字符數據。因為只需要一種編碼,對編碼和解碼字符序列的處理可以直接建立在 XBIS 處理中,從而不需要一個單獨的處理層次。最後,XBIS 不需要逐個字符地檢查多種狀態變化類型,而這對於文本 XML 是必需的。
在討論中,一些開發人員提出 XBIS 取得速度上的優勢是因為沒有執行 XML 處理程序如解析器所需要的結構良好性檢查。從某種意義上說,是有意這樣設計的,在處理文檔的 XBIS 表示時這類結構良好性檢查多數都不需要,因為這種格式的編碼不可能有多種類型的結構良好性錯誤。其他類型的錯誤可能是因為向 XBIS 編碼程序提供不當的輸入造成的(如元素名或屬性名中的非法字符),但是檢查這類錯誤不需要多大的開銷。比如對於元素名和屬性名,名稱只有一次作為文本寫入文檔的編碼形式,當再次使用時將使用一個整數值引用。因此在第一次使用時檢查名稱是否包含非法字符非常簡單。同樣的原理也適用於 XBIS 其他類型的結構良好性檢查。
前景
在第 1 部分已經提到,對 XML 數據替代表示的興趣是一個越來越熱門的話題。甚至已經成立一個新的 W3C 工作組(XML Binary Characterization Working Group),針對文本 XML 一些替代表示的標准化研究用例、准備測定的方法和可能的開發章程。
這些標准將采用何種形式目前還言之過早。XBIS 式的方法保留了 XML 文檔的完整意義(盡管不是所有的語法)具有某些很好的優勢,但是基於模式的二進制編碼(請參閱第 1 部分“ 的數據至上”一節)可以提供某種更緊湊的表示,並可能具有更快的輸入輸出速度。這類方法之所以可能比 XBIS 更快,是因為可以跳過二進制值和文本的轉換。
屬於這兩種類型的項目正在與 Abstract Syntax Notation One(抽象語言符號,ASN.1)結合進行。這是用於消息抽象描述的語言,可能使用各種不同的規則集編碼(包括到二進制編碼的轉換規則)。ASN.1 已經在電信行業和相關領域得到廣泛應用,最近為了處理 XML 進行了調整。一個稱為 Fast Infoset 的項目保留了 XML 文檔的完整含義(至少大部分含義)。另一個項目 Fast Schema(或者 X.694)直接把數據寫成一種編碼形式,從模式生成文檔的編碼和解碼規則。目前為止關於 ASN.1 的研究還沒有多少公開的可證實的信息,但將來很可能會改變。
現有的方法(包括經過公開討論的 ASN.1 實現)看起來都沒有真正充分利用基於模式的二進制編碼的潛能,因為它們在數據對象和實際的編碼形式之間都要經過一個轉換層。使用類增強技術(如我的 JiBX 數據綁定框架中實現的那些技術,請參閱 參考資料)改進這種方法是可能的。JiBX 提供了非常高的性能,部分原因是使用直接嵌入在類文件中的實現對象和 XML 轉換的代碼。將同樣的方法應用於二進制編碼,可以使類有效地把自身序列化為編碼或者從編碼轉換為類。我估計對於等價的數據,這種實現至少要比 XBIS 快幾倍。
使用基於模式的二進制編碼必然會損失與文本 XML 的兼容性,這樣的性能改進還值得嗎?它涉及到很多棘手的問題。比方說,從模式生成二進制編碼這種方法的討論常常涉及到 Web 服務。但是,在將來的 Web 服務中,安全性可能具有更重要的地位,二進制編碼一般會破壞 XML Canonicalization 原則,而這是該領域多數標准的基礎。保留 XML 文檔完整含義的 XBIS 式的方法性能可能差一些,但 確實能夠與 Canonicalization 及其他標准很好地協作。因此,很可能這兩種類型的方法將結合使用。
結束語
測試結果表明,對 XML 使用文本之外的表示,無論從數據大小還是處理開銷上看都可以獲得明顯的好處。標准文本壓縮技術可以極大減少文檔的大小,代價是額外的處理開銷。特定 XML 編碼如 XBIS 可以顯著降低處理的開銷,並適當壓縮文檔大小。對於只交換已知類型文檔的情況,針對特定文檔結構量身定做的基於模式的編碼在將來有可能提供更好的性能。
不幸的是,可以減少處理開銷的編碼還沒有標准化。一旦標准化,需要減少 XML 處理開銷的應用程序就可以獨立了(假設存在這樣的應用程序,很多專家認為情況並非如此)。現在,任何這類應用程序都可以選擇目前正在開發的一種編碼,或者生成自己的數據直接編碼,完全避開 XML。
下載
名字 大小 下載方法 x-trans2fullxbis.zip 2815KB HTTP