在過去的幾年裡,Google一直忙於建設已經成為眾所周知的谷歌大腦團隊,並通過觀看大量的視頻來深度學習,直到大腦能識別什麼是貓的臉,什麼是人的臉。
谷歌已經雇傭很多人來增強谷歌大腦的能力,在今年前一段時間,谷歌還出重金在英國進行人才收購。如外界所傳言的那樣:谷歌大腦還開始直接與谷歌的搜索團隊進行了深度合作。
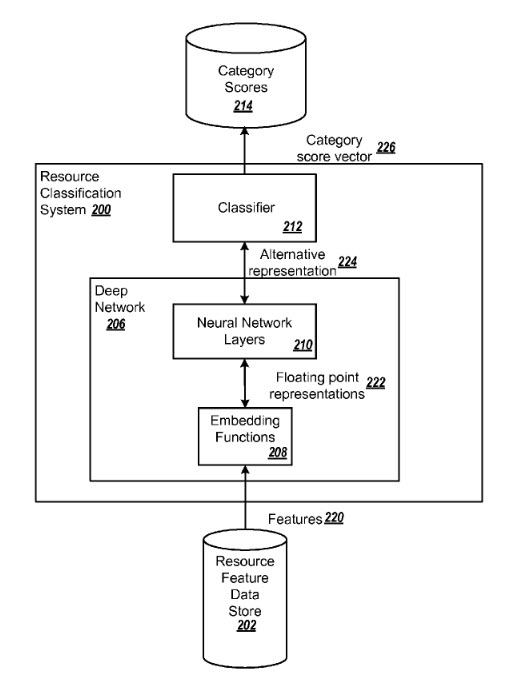
該專利描述的方法包括:
1,接收輸入包含多個資源的特征,其中每個資源的特征都含有相應的屬性;
2,利用嵌入函數給每一個資源特征屬性賦予一個或幾個數值;
3,使用一個或多個神經網絡層把資源特征屬性值進行處理,其中采用一個或多個非線性的轉換來處理浮點值;
4,給輸入的數值預先設置多個分類器,每個分類器有不同的評分方案,其中給每個類別設定上下閥值,以此閥值來判斷資源該屬於哪個類別。
預設的資源分類可能包含不同類別資源作弊的特征,也可能僅僅包含本類資源的作弊特征。不同類別的分數可以應用在以下幾個方面:
1,來決定這個網頁是否會被索引;
2,來決定這個網頁是否會被展示在搜索結果頁面上。
深層網絡能有效地將資源分類。例如,資源可以被有效地分類為垃圾內容或者非垃圾內容。垃圾內容又可以進行細分為不同的類型,而垃圾資源則屬於其中的一種或多種。專利告訴我們:
使用深層網絡分類系統,可以讓搜索結果能夠更好地滿足用戶對信息的需求。比如我們可以通過檢測垃圾的資源,讓這些資源不展示的搜索結果中,或者讓某類搜索資源只出現在這類信息的 搜索結果中。
文摘:
方法、系統和設備,包括計算機程序編碼在計算機存儲媒體,得分概念術語,都在使用深網絡。
其中的一種的方法包括:
1,接收輸入包含多個資源的特征,其中每個資源的特征都含有相應的屬性;
2,利用嵌入函數給每一個資源特征屬性賦予一個或幾個數值;
3,使用一個或多個神經網絡層把資源特征屬性值進行處理,其中采用一個或多個非線性的轉換來處理浮點值;
4,給輸入的數值預先設置多個分類器,每個分類器有不同的評分方案,其中給每個類別設定上下閥值,以此閥值來判斷資源該屬於哪個類別。
專利告訴我們,這個資源資源分類系統可以讓我們辨別出哪些是垃圾資源,比如:
•資源內容很垃圾;
•資源包含很多垃圾鏈接;
•很難判斷的垃圾內容;
•諸如此類的。
一個網站上的網頁其實包含很多標記化的內容,比如網址的URL、網頁的標題、網站的域名、網頁內容的類別、網站的年齡等。這些網頁所具有的標記都會被用來計算一個網頁是否是垃圾內容 ,從而確定是否對網頁進行索引或降低網頁關鍵詞的排名。
例如我們對網頁所代表的標記特征進行打分,然後通過生深層網絡建立決策進行對網頁綜合評分,我們給總分設立一些閥值,如果超過一定的閥值就可以直接不對網頁進行索引。
同理,我們也可以通過分類系統對網頁內容進行分類,如果網頁內容分類與用戶搜索的分類相同,那麼就可以提升這個網頁的排名;而如果一個網頁的分類與用戶搜索的分類不相同,就可降低這個網頁的排名。根據這樣的處理,用戶將會更加容易尋找到符合他們特定需求的內容。
但專利本身沒有提供太多的處理細節和這個機器學習模型的具體功能。
- 上一頁:崔學超:SEO增加外鏈的方法
- 下一頁:張江雷:SEO外鏈推廣工具有哪些