我想說的是無論搜索引擎怎樣變化,大概的收錄原理是不會變的:
1、找到網站的URL並下載頁面。
2、判斷頁面質量是否達到收錄標准收錄頁面,否則刪除。
3、判斷收錄頁面是否更新,更新頁面快照。
以上三條是搜索引擎收錄頁面基本的規律,無論百度還是谷歌都不會違背。那麼我們就可以以以上三條作為依據詳細的解釋一下搜索引擎的工作原理。
首先搜索引擎的組成:
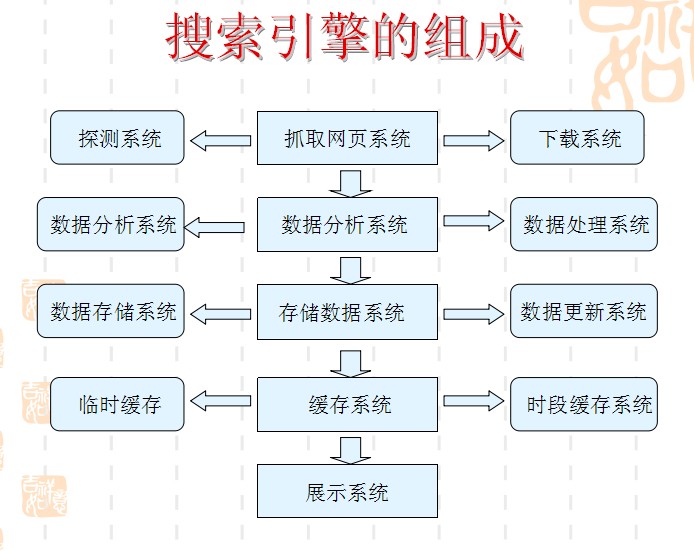
圖1
如圖1所示:搜索引擎可以分為基本的五大部分,既抓取網頁系統,數據分析系統,存儲數據系統,緩存系統,展示系統。
1、抓取網頁系統:分為探測系統和下載系統,探測系統就是我們平常說的蜘蛛,蜘蛛在互聯網上爬行時探測到一個網站的URL,就會把URL所指向的頁面利用下載系統,下載到搜索引擎的服務器上,然後將頁面交給數據分析系統。
2、數據分析系統:分為數據分析和數據處理兩個系統,當數據分析系統從抓取網頁系統那獲取到被下載的頁面,首先進行數據分析去除不相關的文字或網站重復內容,進行頁面文字的處理,然後對處理過後的頁面內容進行判斷,是否達到收錄標准,達到交給存儲系統,沒有達到刪除。
3、存儲數據系統:將收錄的頁面進行保存,然後定時進行判斷存儲的頁面是否有更新。
4、緩存系統:存儲搜索引擎認為高價值的內容,當用戶搜索某個關鍵詞時經常看到收錄量有幾千萬,但是搜索引擎顯示的只有1000條,這也就是說只有1000條被放在了緩存系統上,用戶可以最快速的查找到他們想要的內容。
5、展示系統:用戶搜索返回到顯示器上的信息。
這是搜索引擎的系統的組成,那麼一個頁面是如何被搜索引擎發現並收錄的呢???
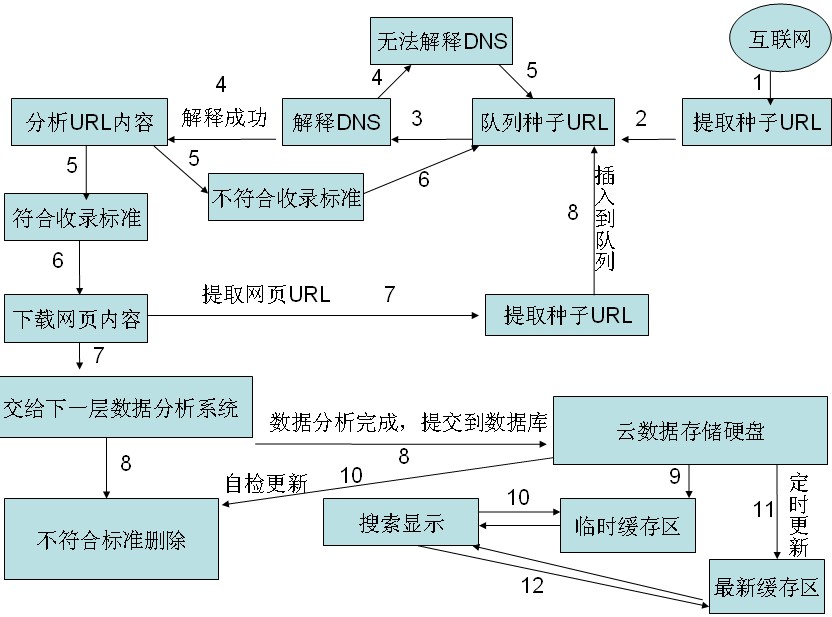
圖2
圖2,蜘蛛在整個互聯網上爬行遇見你網站的一個URL,首先把URL提取出來根據網站權重和相關性插入到URL隊列中,然後是判斷你網站的這條 URL是否能夠解析成功,如果能解析成功,蜘蛛會爬到你網站,這裡需要說一下,蜘蛛並不是直接去分析你網頁的內容,而是去尋找你網站robots文件,根據你網站的robots規則判斷是否抓取你這個頁面,如果robots文件不存在,則會返回一個404錯誤,但是搜索引擎已經會繼續抓取你的網站內容。
搜索引擎抓取了網頁內容之後會對網頁進行一個簡單的判斷是否達到了收錄標准,如果不符合則繼續把URL加入到URL 隊列中,如果符合收錄就會下載網頁內容。
當搜索引擎拿到下載網頁內容的時候,會提取出頁面上的URL,繼續插入到URL隊列中,然後把頁面上的數據,進行進一步分析,判斷網頁內容是否達到收錄標准,如果達到收錄標准則把頁面存儲到硬盤中。
當用戶搜索某個關鍵詞時,搜索引擎為了減少查詢時間,將一部分相關性比較高的內容放到臨時緩存區,大家都知道從計算機的緩存中讀取數據,比在硬盤中讀取數據快很多。所以搜索引擎只將緩存中的一部分顯示給用戶。被存儲在硬盤中的頁面,搜索引擎會根據網站權重定時對其進判斷是否有更新,是否達到了放入緩存區的標准,如果搜索引擎在判斷是否有更新的同時發現網站頁面被刪除或網頁達不到被收錄的標准也會被刪除。
以上就是搜索引擎的組成和頁面收錄原理,希望每一位seo人員都應掌握。
文章原創自任敬林博客,轉載請注明出處:http://www.renjinglin.com/11.html
注:更多精彩文章請關注建站教程欄目。