10月20日,我對博客進行了大規模調整,就如同對待亟待成長的樹一般修枝剪葉,以期能有較好的成長趨勢。其中robots.txt被我充分的利用起來。
如今一個工作周即將過去,robots.txt文件規則是否正確,是否已經生效?百度谷歌等搜素引擎是否響應了robots.txt規則進行索引調整?作為站長我需要深入研究一番,以便動態掌握博客收錄狀態。
經調查發現,谷歌對robots.txt反應比較迅速,第三天在網站管理工具裡找到了跡象。百度表現不盡如人意,說百度不認robots.txt規則那是瞎扯,但反應周期如此之長,難免會留下反應慢不作為的猜疑。
看谷歌對robots.txt規則之反應
在20日做的調整中,有兩條規則我後來做了刪除。打開我博客的robots.txt,和20日進行調整寫下的對比,可知其中變化。
作此調整的原因在於,如按照20日的寫法,第二天我發現,網站管理員工具Sitemaps裡三個被選中的地址前出現了叉號——被robots.txt文件規則給阻止了——這個沒必要嘛。當時的截圖找不到了,下面三個選中的可以看一下:
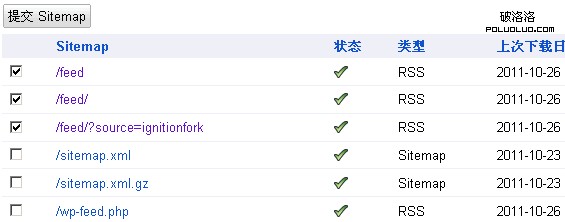
提交的sitemap網站地圖
響應robots.txt規則,谷歌停止了2000 多個連接地址的抓取。那500多個找不到地址,是因為前段時間刪除文章標簽tags後遺症。下面是截圖:
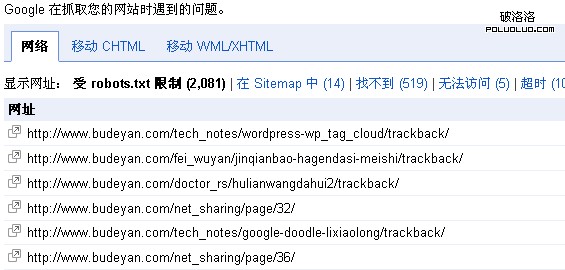
2000多個連接地址被robots.txt規則限制
翻遍每一頁,沒有發現問題——除了一些/?p=的短連接讓人心疼外,一切完美無暇。嚴格來說,應該是robots.txt規則不存在問題,谷歌不折不扣的執行了robots.txt規則。
谷歌查詢“site:***.com inurl:?p” 僅找到殘缺的14條(無標題或摘要)。不久的將來這些地址將被清除。
看百度對robots.txt規則之反應
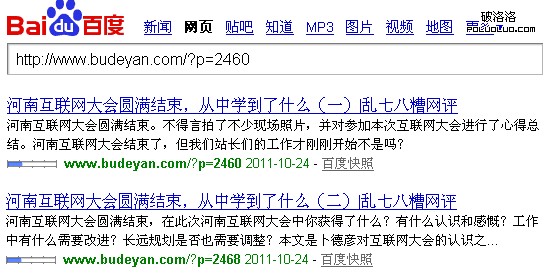
20日就有robots.txt文件規則了,這是什麼情況?
規則20日制定,上面這圖不知是穿越了,還是我眼花了?我查過IIS日志記錄,百度20日後曾多次下載robot.txt文件,服務器返回的是200成功狀態碼。
難怪百度不招各位站長待見。
百度“親愛的站長,我是你爹”高高在上的態度,是否應該轉變一下了?
原文地址:不得言博客
感謝 不得言 的投稿