學習seo的人經常在網上看到一句話:搜索引擎蜘蛛跟浏覽器差不多,都是抓取頁面。那麼到底哪些一樣哪些不一樣?Ethan就通過浏覽器幫助大家理解搜索引擎蜘蛛怎樣抓取頁面。
首先看一張圖,是用firebug(firefox浏覽器的一個著名插件)記錄下來的浏覽器抓取我網站的情況。
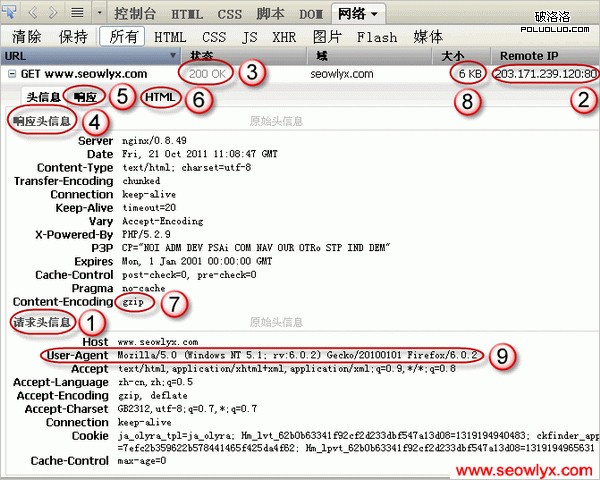
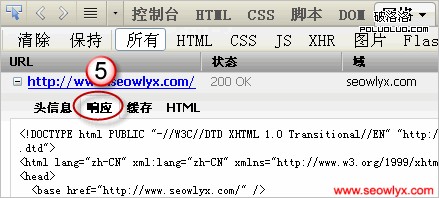
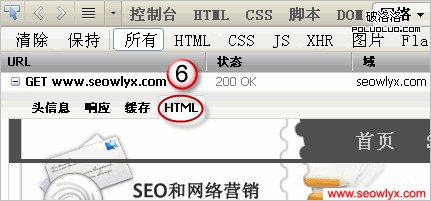
針對圖中標識,Ethan解釋如下。
1.http協議開始,HTTP協議是典型的請求/響應模式,客戶端請求服務器,然後客戶端和服務器建立臨時通道,然後服務器返回響應。這裡浏覽器是一種客戶端程序,搜索引擎蜘蛛也是一種客戶端程序。客戶端向服務器發送請求行,然後是請求頭信息。圖中左上角有“GET www.***.com”,反映了請求行的內容,真正的請求行是下面這行,firebug沒有明示:
“GET / HTTP/1.1”
這行的格式是:
請求方法(get、post等)+一個空格+請求的URL(這裡“/”表示首頁)+一個空格+http協議版本(現在通常是HTTP/1.1,就是http協議1.1版)
記住這個格式,我們在服務器日志裡還會看到這種格式的數據。
請求行後面緊跟著請求頭信息,其中第一行是host字段,指明了服務器是www.***.com,這是個域名,通過DNS域名解析,變成ip地址,也就是服務器的物理地址。
2.ip地址,後面冒號加80,表明訪問的是服務器的80端口。服務器一直處於待命狀態,偵聽80端口,一旦發現有符合HTTP協議的頭信息發過來,就和客戶端建立一個臨時通道,然後進行內部處理,並把結果通過臨時通道返回給客戶端。在這個處理的同時,服務器還可以接受其它HTTP請求。
3.客戶端開始接收響應信息,最先過來的是狀態行,真正的狀態行是下面這行,firebug沒有明示:
“HTTP/1.1 200 OK”
這裡的200就是狀態碼,表示網頁順利打開。
4.然後客戶端收到響應頭信息。
5.最後客戶端收到響應主體,也就是html代碼。
6.注意這裡浏覽器和搜索引擎蜘蛛不同,浏覽器會對html代碼進行處理,呈現出我們看得懂的網頁;搜索引擎蜘蛛則只負責抓取,把html代碼存在數據庫裡,自己快速去抓取下一個網頁。搜索引擎在各地都有蜘蛛服務器,每個服務器同時放出很多蜘蛛,日夜不停地抓取網頁。
7.注意響應頭信息裡有一行gzip,表示html代碼經過了gzip壓縮。不過沒有關系,浏覽器和搜索引擎蜘蛛都可以解壓縮gzip文件。
8.html代碼的大小,如果不壓縮,遠不止6k。搜索引擎對網頁文件大小有個上限,一種說法是128k(未壓縮),超過128k的內容不再抓取。
9.注意User-Agent,正是請求頭信息裡的這個字段,告訴服務器抓取網頁的是浏覽器還是搜索引擎蜘蛛。有的服務器為了不讓百度蜘蛛抓取,會封禁百度蜘蛛的User-Agent,參見百度站長俱樂部發布的百度Spider User-Agent字段更新通知。
本文為www.seowlyx.com的站長梁波(Ethan)原創,轉載請注明,謝謝!
- 上一頁:原創與偽原創到底相距有多遠
- 下一頁:百度新知-百度新產品解讀