對於真假百度蜘蛛,相信SEO及站長們已經有明確的手段去辨別了。百度也在官方通告了如何去判別偽裝成百度蜘蛛的抓取,詳情請參考這篇文章:http://www.baidu.com/search/spider.htm
假蜘蛛對我們網站的危害是巨大的,具體有:
1.占用網站帶寬,導致網站流量上升,增加額外開銷
2.在有限帶寬的前提下,阻礙了正常蜘蛛的抓取
3.誤導了我們在對網站開展SEO工作時的思路
4.部分偽裝成假蜘蛛的采集工具剽竊了我們的工作
我們看到,網上有很多人在分享如何“捉住”假蜘蛛的文章,但這些文章只是千篇一律的描述了“捉住”假蜘蛛的過程及操作方法。卻沒有分享從如何真正的判別蜘蛛的真偽。
作者本人最近在對一個電商網站進行SEO優化時,就碰到了這樣一個案例,險些導致將真蜘蛛錯當假蜘蛛來處理。
一、發現“假蜘蛛”
SEO優化要依靠大量的分析和數據來實現,其中日志分析是重中之重,在日志中我們可以看到很多平時統計工具無法看到的數據和事實。
每周三我都要對該電子商務網站進行周日志的分析,以便來統計上一周的優化效果,在本周進行對網站日志進行分析查看時,我發現了幾個不屬於認識中的“蜘蛛IP”,如圖:

我們知道,百度蜘蛛一般來自於202.181.108.* 和123.125.71.* 這兩個IP段(順便科普一下,這兩個IP段的百度蜘蛛沒有所謂高權重和降權之分)。顯然這三個IP在“常識”中,不屬於百度蜘蛛所屬的IP段。
為了確保不誤殺百度蜘蛛,筆者用nslookup ip命令反解了此IP,得到以下信息:
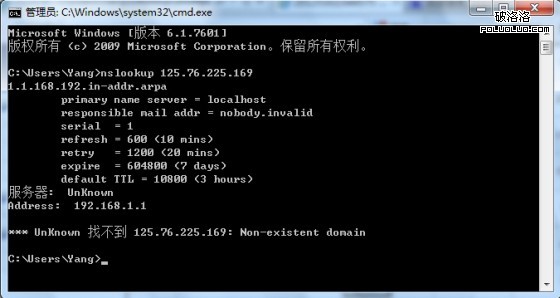
這個時候,基本已經可以確定該IP不屬於百度蜘蛛的IP段,是一個“假蜘蛛”,我們需要屏蔽該IP釋放那些被占用的帶寬。
二,誤會“假蜘蛛”
就在要對以上提到的三個IP進行屏蔽的時候,筆者突然想到,這個電商網站在上周通知我他們要使用安全寶服務,需要將DNS解析到安全寶的服務器上,而安全寶則會根據用戶的訪問情況,選擇距離最近的一個節點進行CDN加速。
在我之前的例行SEO檢查中,發現網站IP被解析到了陝西的一個IP上,而這個網站IP和這次我從網站日志中發現的三個“假蜘蛛”IP屬於同一IP段。
為了驗證這個推測,我又重新仔細查看了網站日志,發現谷歌蜘蛛和搜狗蜘蛛也來自於之前三個IP(之前對網站日志進行了拆分,只查看百度的情況,因為網站是針對百度做SEO的)。
這下子總算清楚了,這些所屬IP的蜘蛛不是假蜘蛛,而是貨真價實的百度蜘蛛、谷歌蜘蛛和其他搜索引擎的蜘蛛。只不過因為他們通過了一次CDN節點,所以造成了他們的來源IP是一致的。
三,虛擬主機如何產生“假蜘蛛”
由此筆者突然想到,之前在閱讀相關文章的時候,經常會看到有站長抱怨發現假蜘蛛,來自XX機房(就那麼一兩家機房)。
這是一件很奇怪的事情,莫非采集工具和假蜘蛛都產自這個機房?事實自然不是那樣的,而是:
1.很大一部分發現假蜘蛛的站長,所使用的是某主機供應商提供的集群主機,或類似性質的虛擬主機。
2.集群性質的虛擬主機,同CDN的道理是相同的,即將客戶的空間和站點資料同步到同一個群組的所有服務器上。
3.蜘蛛的來源不同,一些是直接訪問站點的,另一些是通過一些外鏈訪問站點的。而這些通過外鏈訪問站點的蜘蛛,會就近通過CDN節點訪問。
4.CDN節點每家公司都不一樣,但大致分為地域大區(不是省)和電信、網通這樣的方式劃分。
5.那些通過CDN節點訪問網站的蜘蛛,來源IP自然不是從北京總部出發時的IP。
最終事情得到了很好的解決,該電商網站自優化以來效果一直良好,雖然采用了CDN,但事實證明CDN對搜索引擎而言沒有任何障礙,反而有利於網站速度和提高用戶體驗。
這個SEO案例也同時告訴我們,網上的SEO教程是會過時的,隨著互聯網的進步,我們SEO也要學會理智的去對待一些教程和分享,要有質疑和勇於實踐的精神,同時對互聯網的一些基本的技術知識要有所了解。