在我剛剛接觸SEO這個行業的時候,常常會因為不熟悉各大搜索引擎的抓取原理而做了很多的無用功,針對我的seo優化網站,更新了很多的內容(讓我的網站更加的豐富),針對網站的外鏈操作方式進行了反復的調整,這一切好像都是沒有用的。搜索引擎就好像是不喜歡我網站一樣,所以不管是百度搜索引擎還是谷歌搜索引擎,我覺得不管是seo站長還是seo新手,做為seoer的我們都應該對搜索引擎做的抓取原理進行了解,甚至要去結合搜索引擎的算法不斷調整seo優化網站的操作模式,在這裡我就結合自己工作中的一些經驗,給大家分享一下我對搜索引擎的抓取原理的認識,希望對seoer們能有所幫助!
一、什麼是搜索引擎?
我一開始參加工作的時候,我甚至連搜索引擎是啥都不知道,後來經過師傅和同事的指導後,我對搜索引擎才有了一定的認識,後來自己又去百度了一下才知道搜索引擎的定義:搜索引擎就是指按照一定的策略、運用特定的計算機程序從互聯網上搜集信息,在對搜索到的信息進行組織和處理後,為用戶提供檢索服務,將用戶搜索相關的信息展示給用戶的系統。看完了百度對搜索引擎的定義我想各位seoer們可能還是雲裡霧裡的,不是很清晰,其實簡單通俗的來講就是我們日常獲取信息的一種工具。像百度和谷歌等是搜索引擎的代表。
通過1年多的seo知識的學習,我對搜索引擎定義的理解也有了自己獨特的認識:搜索引擎就像是我們平常在網絡上獲取信息的窗口,它根據我們給出的一些關鍵詞或是少量的信息來進行檢索,給我們提供更多我想要或是與我們搜索相關的信息的工具,平常我們使用最多的就是百度、google、雅虎等一些搜索引擎,以及最近新推出的360搜。做為seoer我的所有工作也都是圍繞搜索引擎在進行的,我的工作就是讓搜索引擎更多地收錄我seo優化網站中的信息,從而被更多用戶搜索到,滿足用戶的搜索需求。說到這,大家是不是覺得我工作好像是為搜索提供信息資料的工作,其實我是一名seo編輯,我每天的工作就是給我的seo優化網站更新最新的信息,每天我也會操作一些外鏈,引導搜索引擎來檢索我的站點,從而讓搜索引擎收錄我的seo優化網站中的信息,在我平時的工作中每天與搜索引擎打交道,不管文章的編輯還是外鏈的操作會用到搜索引擎,一方面是用搜索引擎來檢查自己文章的質量,像一篇文章的重復性,一些關鍵詞的火熱度,通過這些搜索結果給我的軟文編輯工作提供了一個參考,另一方面就是會利用搜索引擎來檢查我的工作的有效性就是被搜索引擎收錄信息有多少(被搜索引擎認可的信息)。我想每一位seoer每天或多或少也都和搜索引擎這樣的接觸,所以做為seoer的我們不僅要知道什麼是搜索引擎,還應該掌握搜索引擎的抓取原理。
二、搜索引擎的抓取原理是怎樣的?
當用戶在搜索引擎中搜索信息時侯,搜索引擎就會派出一個能夠發現新網頁並抓取文件的程序這個程序通常被稱為搜索引擎“蜘蛛”也就是機器人,搜索引擎“蜘蛛”從數據庫中已知的網頁開始出發,就像是平常用戶的浏覽器一樣訪問這些網頁並抓取文件,搜索引擎“蜘蛛”在互聯網中抓取網頁,然後將抓取的網頁放到臨時數據庫中,在抓取的網頁中若還有其他的鏈接,搜索引擎“蜘蛛”會順著這個鏈接進入下一個頁面,再把這個頁面抓取放入臨時庫中,就這樣不斷的循環抓取;就像是一個超市一樣,在超市開業前超市的采購員回去市場上采集一些產品,在采集這些產品過程發現有新的產品,他會將這個新的產品一起采集回來,放在超市中,搜索引擎的臨時數據庫就相當於超市一樣,搜索引擎“蜘蛛”就相當於超市的采購員,通常我都知道超市中如果有一些商品是劣質的或是沒有客戶購買的,超市的負責人會將該商品退出超市,合格的商品就會按照商品的類別進行分類,擺放,將合格的產品呈現給客戶。就像臨時數據庫中的網頁信息一樣如果有不符合規則,就被清除掉;若符合規則,就放入索引區,再通過分類、整理、排序等過程,將符合規則的網頁放到主索引區,也就是用戶直接看到查詢的結果。
下面就用一張簡單的圖片更直觀的說明一下我的觀點:
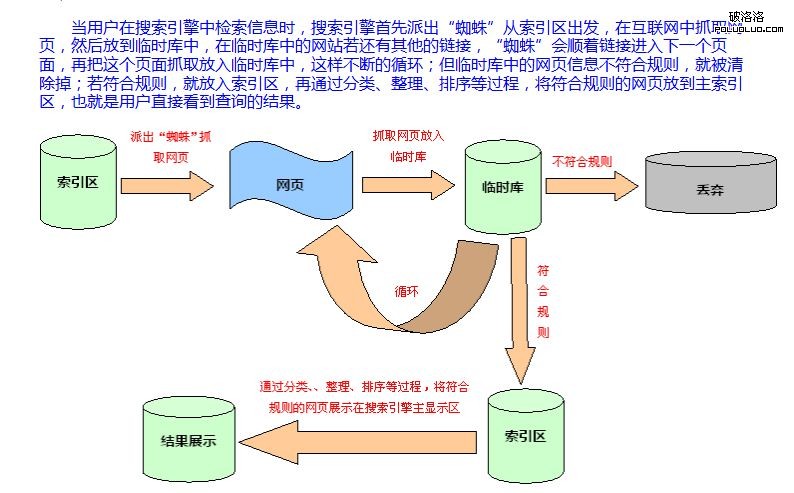
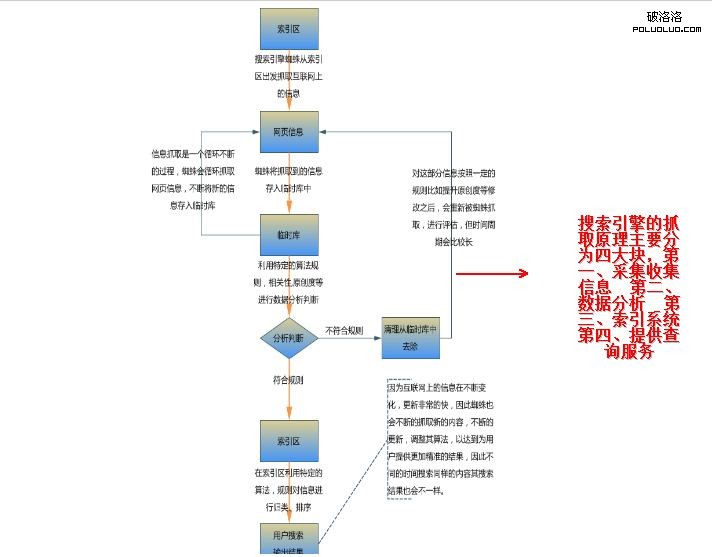
以上是我做seo工作過程中總結的關於我對搜索引擎的抓取原理是認識和理解,希望對seoer們能有所幫助,當然可能我的理解也不是全面,這還需要各位seoer一起探討,互相分享共同成長。