有很多人問過我,說Mr.Zhao啊,百度如何判斷偽原創和原創?百度喜歡什麼樣的文章?什麼樣的文章比較例如獲得長尾詞排名?等等諸如此類的問題。面對這些問題,我常常不知如何回答。如果我給一個比較大方向一些的答案,例如要重視用戶體驗、要有意義等等,那麼提問者會覺得我在應付他,他們往往抱怨說這些太模糊。可是我也沒法再給出具體的內容,畢竟我不是百度,具體算法我又何德何能的為你們指點江山呢?
為此,我開始寫這個“如果是我”系列的文章。在這一系列文章裡,我假設如果是我絞盡腦汁的來為網民提供較好的搜索服務,我會怎麼做,我會怎麼對待文章內容、如何對待外鏈、如何對待網站結構等等諸如此類的站點元素。當然,本人技術有限,我只能寫一點我稍微理解的東西。而百度以及其它的商業搜索引擎,他們有大量比我優秀的人才,相信他們的算法以及處理問題的方式會比我完善很多,而我之所以寫這些,無外乎拋磚引玉,希望大家看後,心裡有一個大概。畢竟在SEO的道路上走過一段時間後,沒有誰能夠當誰的老師,一些觀點僅供參考。
在此,我要鄭重聲明,這個系列文章中所有涉及到的思想、算法與程序,均非本人所寫,全部是我從一些公開的資料裡搜集而得的。同時,相信大家也能理解,如果這些免費公開的東西都能做到如此程度,那麼那些商業機密就更不用提了。
好的,現在開始。
如果是我,我會喜歡什麼樣子的文章呢?我會喜歡我的用戶喜歡的文章,如果硬要加判定標准,那無外乎是兩種:1.原創且用戶喜歡。2.非原創且用戶喜歡。在這裡,我的態度很明顯,偽原創就是非原創。那麼用戶喜歡什麼樣的文章呢?很顯然,一些新觀點、新知識往往是用戶喜歡的,也就是說通常原創文章都是用戶喜歡的,而且即便用戶不喜歡,原創站點作為新鮮內容的制造者,也應該受到一定的保護。那麼非原創的文章用戶就一定不喜歡嗎?誠然否也。一些站點,其內容往往是經過搜集整理後聚合而成的,那麼這些站點對用戶來說就是有價值的,其相對應的文章理應獲得較好的排名。
由此可見,我需要重視兩類文章即可。一是原創文章,二是有價值的信息聚合站點下的文章。
首先要明確一點,本文探討范圍僅限內容頁,而非專題頁、列表頁和首頁。
那麼我在甄別這兩類文章之前,我需要先進行信息的采集。本文對於spider程序部分不進行闡述。當spider程序下載下來網頁信息後,在內容處理的模塊中,我需要先對內容除噪。
內容除噪,並非大家經常性的誤以為僅僅除去代碼而已。對於我來說,我還要出去頁面部分非正文內容的文字。比如導航條、比如底部文字以及各個文章列表。將它們的影響除去後,我將得到一段僅僅包含網頁正文內容的文本段落。寫過采集規則站長朋友應該知道,這個並不難。但搜索引擎畢竟是一款程序,不可能針對每個站寫個類似於的采集規則的東西,所以我需要建立一套除噪算法。
在此之前,我們先明確我們的目的。
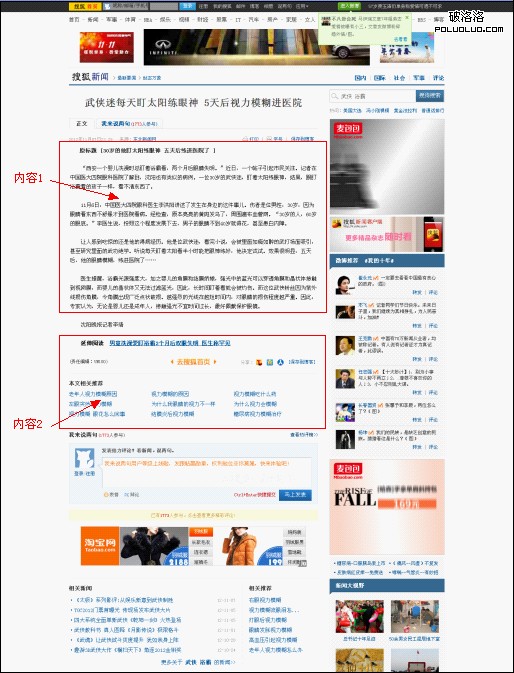
上圖中很明顯內容1是用戶最為需要的,內容2是用戶可能感興趣的,其余均是無效的噪音。那麼針對於此,我們可以發現如下幾特征:
1.所有的調用列表全部是在一個信息塊裡,這個信息塊絕大部分是由標簽組成,即便有游離於標簽的內容,其文字也基本是固定的,且在站內頁面中存在大量重復,較為容易判斷。
2.內容2一般緊鄰著內容1。而且內容2中的鏈接錨文本,與內容1存在相關性。
3.內容1部分,是有文字文本內容和標簽混合而成,且在通常情況下,文本文字內容在網站網頁集合中具有唯一性。
那麼,針對於此,我采用廣為人知的標簽樹方式,將內容頁進行分解。
從網頁的標簽布局上來看,網頁是通過若干的信息塊來提供內容的,而這些信息塊又是由特定的標簽規劃出來的,常見的標簽有div ul li p table tr td 等,我們依照這些標簽,將網頁費解為樹狀結構。
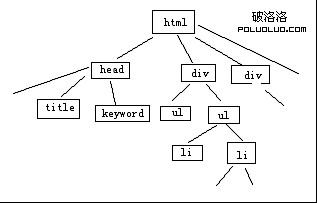
上圖是我手繪的簡單的標簽樹,通過這種方式,我可以非常輕松的識別出各個信息塊。然後我設定一定阙值A為內容比重阙值。內容比重阙值為信息塊中文本字數與標簽出現此處的比值。我設定當網頁中信息塊內容比重阙值大於A時,才會被我列為有效內容塊(此舉是為了杜絕過分的多內鏈,因為如果一篇文章布滿內鏈,則不利於用戶體驗),然後我再比對內容塊中的文本,當其具有唯一性時,此一個或多個內容塊的集合,即為我所需要的“內容1”。
那麼內容2我要如何處理呢?在講解處理內容2之前,我先講解一下內容2的意義。正如我先前所說,如果是一個注重用戶體驗的聚合性網站,那麼他的作用是將現有的互聯網內容經過精心的分類與關聯,來方便用戶更好、更有效的閱讀。針對這樣的站點,即便其文章不是原創而是從互聯網上摘抄的,我也會給予其足夠的重視與排名,因為它良好的聚合內容往往更能滿足用戶的需求。
那麼針對聚合站點,我可以通過“內容2”來進行粗略的判斷。簡而言之,如果是一個良好的聚合站點,首先其內容頁必須存在內容2,同時內容2必須占重要部分。
好了,識別內容2很簡單,對於內容比重阙值低於某個特定值的信息塊,我全部判斷為鏈接模塊。我將內容1通過某些方式(具體方式本文後半部分講解),提取出主題B。我將鏈接模塊中的所有a標簽的錨文本分別進行分詞,如果所有的錨文本均與主題B相符,則將此鏈接模塊判定為內容2。設定鏈接阙值C,鏈接阙值為內容2中標簽出現次數除以所有鏈接模塊所出現的a標簽次數所得的比重,若大於C,則此網站可能為聚合網站,針對內容排名計算時會引用聚合站點特定的算法。
拓展閱讀1開始:
我相信很多SEO從業者剛接觸這行時,就聽說過一件事,就是內容頁面導出鏈接要具有相關性。還有一件事,就是頁面下面要有相關閱讀,來吸引用戶縱深點擊。同時應該還聽人講過,內鏈要適中,不可太多等。
但很少有人會說為什麼,而越來越多的人因為不明其內在道理,而漸漸忽視了這些細節。當然,以前的一些搜索引擎算法在內容上的注重程度不夠,也起到了推波助瀾的作用。但是,如果從陰謀論的角度上來看,我可以假設出這麼一個道理。
絕大部分用戶的搜索頁面,第一頁只有10個結果,除去我自家產品,往往僅剩下7個左右