在本文中主要就如何用SAX解析XML文檔進行說明。
要解析的XML片段如下:
<?XML version="1.0" encoding="UTF-8" standalone="yes"?>
<Books>
<Book id="8542f26f-80d4-4b7d-ab25-f80f72a852ef">
<name id="201">
<strings>
<entry>
<key>en_US</key>
<value> thinking in Java</value>
</entry>
</strings>
</name>
<Author>
<entry>
<key>en_US</key>
<value>Tom</value>
</entry>
</Author>
<icon>
<url>think_Java.PNG</url>
</icon>
</Book>
...
</Books>
應用程序想從這個XML文檔中讀出各個book,並且需要提供查詢功能,即給定書的id,能夠找到作者和書名。
當然,用jdom是很簡單的方式,不過如果我們讀到的是一個stream,並且比較大,那麼我們最好用SAXParser,不需要把整個XML文檔裝入內存。
首先,我們建立一個Book類,保存book相關的信息。
public class Book {
private String id = null;
private String name = null;
private String author = null;
private Image image = null;
// 一系列的get和set方法。略去 public String toString()
{
return "Book [" + "ID=" + id + ", Name=" + name + ", Author=" + author + "]";
}
}
接下來我們新建一個類BooksSAXHandler,它擴展了DefaultHandler,用於解析XML。SAX解析是以事件為基礎的,在這裡我們處理三個事件,分別是startElement,endElement以及characters。為了獲取一個element裡面的text值,我們需要程序知道當前在處理那個結點,但僅僅知道結點也是不夠的,因為可以有同名的結點,故此我們引入currentPath,這樣可以唯一的定位到要處理的結點。下面給出了解析的方法,注意currentPath的用法。
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
currentPath.append(qName + "/");
if (qName.equals(ELEMENT_BOOK)) {
book = new Book();
if (attributes.getQName(0).equals(ELEMENT_ID)) {
book.setID(attributes.getValue(ELEMENT_ID));
}
}
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
currentPath
.delete(currentPath.lastIndexOf(qName), currentPath.length());
if (qName.equals(ELEMENT_BOOK)) {
booksMap.put(book.getID(), book);
book = null;
}
}
public void characters(char[] ch, int start, int length)
throws SAXException {
if (currentPath.toString().equals(NAME_PATH)) {
book.setName(new String(ch, start, length));
} else if (currentPath.toString().equals(AUTHOR_PATH)) {
book.setAuthor(new String(ch, start, length));
}
}
接下來,我們用Javax.xml.parsers.SAXParser來解析這個xml文檔,SAXParser需要兩個參數,一個是要解析的stream流,另外一個就是DefaultHandler的對象。到此為止,我們已經清楚了解析這個XML的全部過程。在附件中有例子的完整代碼。
用戶界面是用jface的TableViewer實現的。這裡簡單介紹一下TableViewer的用法。定義了TableVIEwer之後,關鍵需要設置以下三個方法。
tableVIEwer.setContentProvider(new BooksContentProvider());
tableVIEwer.setLabelProvider(new BooksLabelProvider());
tableVIEwer.setInput(getBooks());
其中getBooks()是提供數據的,返回所有數據的列表,在本例返回List<Book>。
BooksLabelProvider需要實現ITableLabelProvider,主要是返回table的對應列的值。其中有兩個主要的方法,String getColumnText(Object element, int columnIndex) 以及Image getColumnImage(Object element, int columnIndex)。
在本例中,element對應一個Book對象,getColumnText返回table對應列的文本值,包括Book的ID,Name,Author等。getColumnImage 則返回table對應列的Image,這裡對應Book的Image。
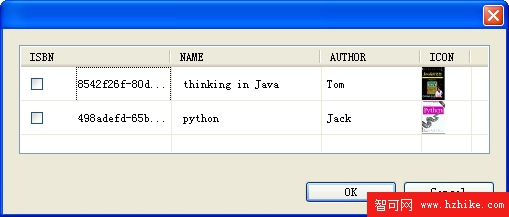
最後的運行結果是: