js中查找最近的共有祖先元素的實現代碼
編輯:關於JavaScript
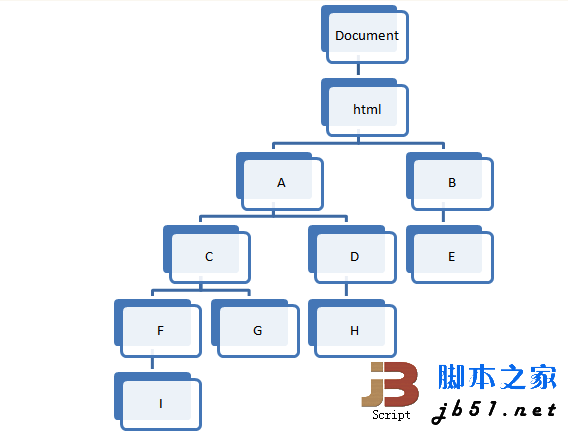
所謂“最近的共有祖先元素”,是指給定一系列元素,找出在樹中深度最大的,但同時為所有這些元素的祖先元素的元素。
比如上圖中,I和G的結果為C,G和H的結果為A,D和E的結果為html,C和B的結果為html等。
測試驅動
對於偏邏輯的題,並沒有十足的把握函數是正確的,因此還是先構造測試的用命,力求讓函數通過測試。
本次就以上圖的結構作為DOM結構,A表示body,B表示head,其他節點均使用div元素,同時以上文中所說的作為測試的輸入和輸出,先構造一下測試:
復制代碼 代碼如下:
function test() {
var result;
result = find('i', 'g');
result.id !== 'c' && alert('fail (i, g)');
result = find('g', 'h');
result.id !== 'a' && alert('fail (g, h)');
result = find('d', 'e');
result.nodeName.toLowerCase() !== 'html' && alert('fail (d, e)');
result = find('c', 'b');
result.nodeName.toLowerCase() !== 'html' && alert('fail (c, b)');
}
基本邏輯
這次的邏輯大致是這樣的:
1、針對每個給定的元素,從父元素到document依次向上遍歷。
2、對遍歷過程中經過的每個元素,保存到一個有序的map中,以元素為鍵,以遍歷到的次數為值。
2、最後遍歷map,找同第一個值與給定元素個數相同的項,就是第一個被所有元素的遍歷都經過的元素,也即最近的共同祖先元素了。
細節問題
在實際過程中,對map的構建比較重要,這裡涉及到2個問題:
1、map不能直接以元素作為鍵,必須轉換為合適的基元類型(如number, string, Regex等)。
2、chrome對object中的鍵會有自動排序,因此盡量避免使用number類型作為鍵。
對於第一個問題,必須給元素綁定一個合適的字段,起到唯一性標識符的作用。好在HTML5提供了data-*屬性,使DOM的元數據承載能力有了很大的提高,可以大膽地添加希望的屬性了。
對於第二個問題,本身也不難,生成的標識符避開number就行了,方便的方法是加個下劃線,或者使用String.fromCharCode轉成字符,無論怎麼樣都無所謂。
實現代碼
代碼有點長,主要是個人比較喜歡偏JAVA的風格,每一個語句每一個分支都清清楚楚,不喜歡用&&或者||來處理條件分支,所以有很多行只有一個大括號之類的情況,其實真正有效的代碼還是精簡的。懶得裝類似toggle之類的插件,也不想看到滾動條,就隨便扔在這了。
復制代碼 代碼如下:
function find() {
var length = arguments.length,
i = 0,
node, //當前節點
parent, //父節點
counter = 0,
uuid, //給DOM的唯一標識符
hash = {}; //最後結果的map
//對每一個元素,向上遍歷至document
//這個雙層的循環是不可避免的
for (; i < length; i++) {
//獲取node
node = arguments[i];
if (typeof node == 'string') {
node = document.getElementById(node);
}
//向上遍歷
while (parent = node.parentElement || node.parentNode) {
//到document就停下來,不然就是死循環
if (parent.nodeType == 9) {
break;
}
//獲取或添加一下標識符
uuid = parent.getAttribute('data-find');
if (!uuid) {
uuid = '_' + (++counter); //避免chrome對hash重排序
parent.setAttribute('data-find', uuid);
}
//增加計數
if (hash[uuid]) {
hash[uuid].count++;
}
else {
hash[uuid] = {node: parent, count: 1};
}
node = parent;
}
}
//hash中只存有各節點向上遍歷經過的父節點,不應該很大
//因此這個循環是比較快的
for (i in hash) {
if (hash[i].count == length) {
return hash[i].node;
}
}
};
點評
測試沒問題,但測試用例是否完善實在不好說,期待網友幫我找出問題來,對於邏輯型的實在是沒啥自信說100%沒問題。
對於取父元素,習慣性兼容IE寫成parentElement || parentNode,這是因為IE的一個BUG,當一個元素剛被創建出來但未進入DOM時,parentNode是不存在的。不過本次函數保證節點在DOM樹中,其實parentElement就沒有必要了。所以有時候習慣性的兼容代碼也不見得就一定是好事,最適合當前環境的代碼才是好代碼。
雖然說2重循環不可避免,但總隱隱感覺循環還是有辦法在特定情況下少做點事,比如向上遍歷的時候發現某個元素已經不可能是所有元素的共有祖先了,那麼就不要再去遞增count值了。
最後的for..in循環有沒有辦法省掉呢?在上面的2重循環中有沒有辦法實時地就通過一個變量始終保存最合適的節點呢?
小編推薦
熱門推薦