SEOER的研究對象就是搜索引擎,因此深入了解搜索引擎工作原理很有必要,網上也有很多介紹這方面的文章,但能稱得上詳細、形象、深入地進行剖析的少之又少。當然,筆者的博文可能也完全達不到所謂的詳細、形象、深入三面俱到,但筆者會盡可能詳盡、深入地闡述各個原理,以便對這些原理能有更深層次的認知。
一、抓取:其實在抓取前面還有一個過程沒有描述在內,那就是爬行,也就是搜索引擎程序發現新網址的過程,只是這個過程大多伴隨著抓取,除非你的這個URL上的內容沒有什麼價值(垃圾內容、重復內容、文字過少內容等)而被搜索引擎抓取程序直接跳過。搜索引擎爬行程序以數據表中已存在或新提交的鏈接順籐摸瓜式地進行爬行以不斷發現新的URL,抓取程序在分析並確定該URL的頁面內容有價值後,便將其整個頁面抓取下來放入到龐大的信息數據表中。新抓取的內容在進入信息數據表時,並不是一股腦地堆積在那,而是按照信息數據庫中表的字段(如:網頁URL、title、描述、正文內容、抓取時間、導出鏈接等)分門別類地將信息存儲起來,以便滿足後期的數據索引操作。
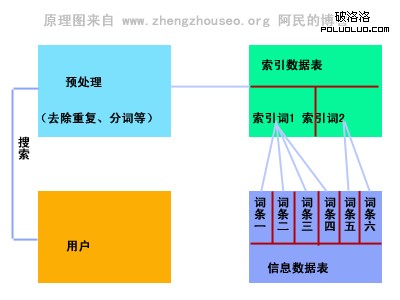
二、索引:在談這個過程前,我們首先要理清搜索引擎索引數據表與信息數據表之間的關系,其實搜索引擎底層的數據存儲本身就是一個關系數據庫,索引數據表和信息數據表是兩個獨立的表,只是索引數據表和信息數據表是一對多的關系,這樣或許更好理解。那麼搜索引擎為什麼需要索引數據表呢?我們不妨從信息量這個角度分析一下,就目前來看,搜索引擎的信息量在百億級,而用戶搜索某個關鍵字時響應速度在短短的2、3秒內,在這短短的2、3內不僅僅要完成數據的查詢,而且還要完成數據的排序(關鍵詞排名)。如果每次都要從這百億級的數據中查詢用戶請求並處理排序,不僅減慢響應速度,而且還浪費了大量的計算資源,對服務器的壓力也會更大。這個時候,搜索引擎就迫切希望將用戶查詢的信息鎖定在一個范圍,這個范圍的信息量或許只有幾千條、幾百條,計算處理起來,效率要高很多,而索引數據表就是為解決這一問題出現的。
根據統計,漢語詞語大約有9萬多個,聽起來很龐大,但對於計算機來講處理起來恐怕會很輕松,而中文用戶的搜索無外乎就是這幾萬個詞語的組合(英文就更簡單了,26個字母的組合)。如果用戶搜索的是一連串兒的句子,那麼要先經過搜索引擎的分詞處理,比如 搜索:華普筆記本電腦,分詞技術首先會按照漢語習慣進行劃分,劃分為:華普、筆記本、電腦,那麼這三個常見詞語在搜索引擎索引數據庫表中都有對應的詞條,此時搜索引擎將從信息數據表中篩選出關聯索引數據表中3個詞語的全部詞條並取其交集詞條展現給用戶,如果用戶單一搜索一個詞語,那搜索引擎處理起來就更為簡單,直接從信息數據表中篩選出索引數據表中該詞所對應的詞條即可。
三、排名:闡述這一原理,不得不說下搜索引擎爬行、抓取過程,影響關鍵詞排名的因素很多,如:站內優化情況、外鏈質量及數量、pr等,那麼這些排名因素搜索引擎也必須抓入數據庫,納入數據表作為特定URL的排名依據,其實影響網頁排名指標的獲取過程就是搜索引擎爬行、抓取的過程。最難理解的可能就是外鏈這一塊兒,因為在抓取網頁時,搜索引擎是捕捉不到他的導入鏈接的,其實搜索引擎在抓取一個頁面時,已經將該頁面的導出鏈接投票計算到了相應的頁面,並將這一有效投票寫入到了所指向的URL字段中(比如:votes字段),便於排名程序加以計算。當然,影響排名的因素很多,排名計算的具體方式我們也無從得知,因此這些不在我們的討論之列。關於排名,大家可能還有一個問題,就是每個詞語的排名是事先排序好了,還是當用戶搜索時才進行排序,筆者給出的答案是後者,或許這一個現象可以揭秘筆者的答案:每一天甚至每一小時關鍵字排名都會出現波動。
筆者帶病寫博文,因此語言上可能有點兒費解,最後筆者PS張圖給大家看下,作為宏觀了解搜索引擎的三大原理示意圖,如文中圖所示。
本文來自 http://www.zhengzhouseo.org/post/sousuoyinqing-jingyan24.html 阿民的博客,轉載請注明出處,謝謝!
感謝 阿民 的投稿
- 上一頁:SEO人才缺口催生培訓新市場
- 下一頁:關鍵詞放在網頁的哪些位置比較好