跨語言信息檢索,是信息檢索領域中的一個研究課題。近10幾年來,由於互聯網的飛速發展,這方面的研究受到了學術界的廣泛重視。將這項技術應用於搜索,可以幫助我們查找到更多的有用信息,例如外語相關頁面、多語言頁面以及語言無關的資源(如圖片)等等。這些信息可以大大豐富搜索的結果,滿足用戶多樣的需求。在跨語言信息檢索的研究中,有一些研究成果已經趨於成熟,達到可以應用的狀態。事實上,Yahoo和Google在5,6年前就已經開始提供多語言的搜索服務。毫無疑問,在這方面他們已經走在了世界的前列。目前,百度的各項國際化業務正在如火如荼的開展,對跨語言技術來說,正是用武之地。相信不久的將來,它將會在搜索國際化進程中扮演舉足輕重的角色。來,就讓我們一探究竟吧。
假如你搜索“中菲黃巖島對峙”,如果你是一個普通用戶,你想知道的可能是這個事件的歷史淵源和發展動態;如果你是一個文藝用戶,你想知道的可能是中國憤青們的愛國言論。沒問題,現有的中文搜索完全可以滿足你的需求。
但是,如果你是一個XX用戶,你對中國網站的內容不滿足,很想知道外國的媒體是怎麼報道的,外國民眾是怎麼談論這個事件的。那麼不好意思,中文搜索引擎就無能為力了。這是因為,中文搜索引擎都是中文作為基礎來構建的,它往往只收錄了中文數據,只考慮了中文的特性,只考慮了該中國網民的需求。但是,當我們想要做跨語言搜索時,搜索就變得困難了。且不說我們沒有抓取那麼多外文數據。即使我們有數據了,由於不同語言之間的巨大差異,以及各個國家各種各樣的網絡習慣,我們也很難精准地搜索到相關的外文信息。也就是說,語言的不同給搜索帶來了一道鴻溝。
那麼,這道鴻溝就不能跨越了麼?當然不是。事實上很多年前人們就已經開始考慮這個問題了。在學術界,對這個問題有個專有名詞,叫跨語言信息檢索(Cross-Language Information Retrieval)。早在上個世紀60年代,現代信息檢索的奠基人,美國康奈爾大學的Salton教授發表了一篇《Automatic processing of foreign language documents》,首先打開了跨語言信息檢索的大門。但是由於那個時代還沒有互聯網,研究也只能停留在簡單實驗階段,甚至跨語言信息檢索的概念還沒有正式提出。到了上世紀90年代,美國國家標准技術研究所(National Institute of Standards and Technology)和美國情報局前沿研發活動中心(Advanced Research and Development Activity center of the U.S. Department of Defense)聯合舉辦了信息檢索領域最重要的會議——“TREC”會議(The Text REtrieval Conference)。到了1996年,在瑞士所舉辦的SIGIR-96會議中,首次出現了以跨語檢索為研究主題的研討會。而到了2000年,歐盟成立了“跨語言評估論壇”(Cross Language Evaluation Forum),每年定期舉辦跨語檢索研討會,並且推動跨語檢索技術評比。從此,跨語言信息檢索變成了信息檢索領域的一個炙手可熱的研究課題,無數英雄豪傑參與其中。
閒話少說,我們該進入正題了:對於跨語言信息檢索問題該如何解決呢?接下來讓我們揭開它的面紗。
在說跨語言信息檢索之前,我們先回顧一下經典信息檢索是怎樣做的,如圖1所示:首先,對於用戶的query,我們要對它進行特征提取,使之變成一個特征向量,用於匹配文檔。其次,對於已經抓取的文檔,我們也對它進行特征提取,並給予這些特征一些權重,來表示它們的重要程度。再次,我們對query的特征和文檔的特征進行相似度計算,來判斷哪些文檔跟query相關,哪些不相關。信息檢索最常用的相似度計算方法是求cosine,其它還可以從語義主題的角度去描述相似性,這個就不詳細介紹了。有了相似度,我們可以根據相似度對文檔進行排序,並將最相關的一些作為檢索結果。對於檢索結果,用戶可能會提供一些反饋,比如用戶的點擊。這些反饋可以告訴我們,在搜索結果裡面哪些是用戶需要的。這些信息可以用來衡量檢索的效果,來對檢索模型進一步提升。
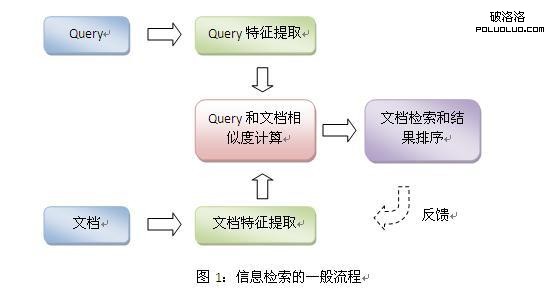
在信息檢索的流程中,我們可以看出跨語言檢索的難點:當query的語言和文檔的語言不同時,query和文檔的特征空間是不同的。中文的特征集合(某個中文詞語出現與否)與英文的特征集合(某個英文詞語出現與否)的交集極少,這導致原有的相似度計算方式在跨語言時失效了。
那麼這個問題怎麼解決呢?
對於跨語言,我們自然而然想到的一種方式就是:翻譯。我們可以通過翻譯的方式把一個語言的詞語映射到另一語言上,從而讓query和文檔處於同一個特征空間中,然後再利用單語下的檢索模型進行檢索和排序,這樣就可以實現跨語言檢索了。
Query翻譯——把query翻譯到文檔的語言下,然後用這些翻譯後的query在文檔中進行檢索。對於query中的詞語,我們可以選擇若干可能的翻譯,用於擴大召回。這可以看作是一種query擴展。
文檔翻譯——把文檔翻譯到query的語言下,然後用原有query對翻譯的文檔進行檢索。文檔的翻譯一般是在線下進行的。一篇源語言的文檔通過自動的翻譯(如機器翻譯)變換成一篇目標語言下的文檔。
這兩種方式都是可以達到跨語言檢索目的的,我們在實踐中應該采用哪種方式呢?下面我們分析一下這兩種方式的優劣:

從上述優劣比較中我們可以看出,文檔翻譯雖然可能提供更准確的翻譯,但它需要更多的線下處理時間,需要更多的存儲空間,實用性較差。鑒於此,無論是學術界還是工業界,一般采用的都是Query翻譯的方式。
1