描述 嵌入在你的web頁面中的導航元素能夠降低你的搜索引擎評價排名並且降低你的網站的響應性能。本文作者想同你一起探討如何使用AJax技術來解決這兩個問題。
許多設計良好的web站點都包含大量的與實際內容相聯系的可導航信息。用於導航的Html標記能影響你的搜索引擎評價,而且能夠改進訪問者的頁面下載體驗感。在本文中,你會看到如何使用AJax來創建更為集中的更快速加載的web頁面。
一、 分離導航與內容
讓我們使用一個例子作為開始。請考慮你現在閱讀的文章,它有下列一些內容:
· 一個其上有一些預定義的到Informit的各個部分的鏈接的頁眉。
· 在頁眉下有一行,把本文放到Informit的目錄結構之中(實際上,這是唯一的與目錄相關的可導航元素)。
· 一個位於右首的側欄,其中有一些連接到流行文章和推薦內容的鏈接。
· 一個頁腳,還有一些永遠不會改變的鏈接。
上面的"混合"很可能會影響搜索引擎索引你的數據的方式:
· 因為搜索引擎不能區別內容與導航文本,所以它們會把它們在你的頁面中找到的一切進行索引。既然目錄中的關鍵字與不相關的可導航關鍵字混合在一起,那麼內容之間的關聯大大減少。一些搜索引擎宣稱,它們能夠在被搜索到的頁面(例如,固定的頁眉和頁腳)中發現重復的文本並且刪除它們。但是,不要依賴這種可能性;即使它們實現了這種技術,也很可能不會一直可靠。
· web頁面中的外向鏈接影響你的內容的頁面評價。盡管這可能提高流行的文章的評價排名(因為許多頁面都鏈接到它們),但是所有的頁面都鏈接到的內容(例如,隱私策略)通常得到最高的頁面評價-這可能不是你一直關心的問題。在我的一個web站點中,最高的評價頁面是用於把消息發送到web管理員的表單-而不是你想讓用戶首先在Google上找到的內容。
注意
即使你不使用站點地圖,你也可以通過Google的站點地圖用戶接口來了解一下你的頁面的頁面排名情況。
添加到一個web頁面的可導航元素還可能影響使用低速互聯網存取的用戶,而如果web頁面不使用DIV元素(Informit使用之)而使用表格時更是如此。在這種情況中,在把它顯示給用戶之前,整個表格必須被加載到一些web浏覽器中。
傳統地,web設計者一般都使用框架集或通過構建整套的導航架構(廣泛使用JavaScript代碼)來實現導航與內容的分離。這兩條途徑都存在其缺點;因此,許多大型網站避免使用框架集就不足為奇了。
借助於在AJax框架中使用的技術,你可以為這一問題提供一種方案:
· 每一個web頁面僅包含可導航元素和實際內容的占位符。
· 在web頁面通過嵌入式框架(IFRAME)或使用XMLHttpRequest對象加載後,再裝載這些可導航元素。
· 然後,可導航元素的內容被合並到web頁面內容中,從而產生一個不嵌入任何幀的干淨的頁面。
在使用這種方法重新設計你的web頁面之前,你需要考慮下列問題:
· 搜索引擎僅將看到初始的web頁面。你必須確保,該頁面中包含到相關頁面或到一個網站地圖的鏈接。Informit網站中文章頁眉上方的導航線和在頁面的文章信息部分中的鏈接正好可以較好地實現這一目的。
· 在他們的浏覽器中禁止調用JavaScript的訪問者將具有與搜索引擎相同的頁面視圖。你必須確保他們有受限的視圖不會給你的網站的功能造成較大影響。
· 你可能想在你的頁面上保留一些靜態內容。例如,Informit標識和版權信息必須一直顯示給所有的訪問者。
當你確定好應該把你的導航結構哪些部分依附到頁面上以及哪些部分應該與之分開之後,你就可以開始下一步驟了。
二、 設計你的Web頁面
實現分離內容和導航的第一步是,在web頁面上創建將插入可導航元素的占位符。對於每一個可導航元素的連續區域,你應該創建一個具有唯一id的獨立DIV元素;這樣以來,以後你可以在你的JavaScript代碼中標識它。為了防止過度晃動,在創作頁面期間,目錄上方或右邊的DIV元素的尺寸應該調整到非常接近你的可導航元素的實際大小;這樣,當你使用希望的Html代碼來代替它們時內容就不會移動位置。為此,一種最巧妙的方法是把一個空的適當大小的DIV元素插入到該占位符處。
對於Informit網站來說,其頁面結構已經是良好設計的,且DIV元素已經非常到位,如圖1所示。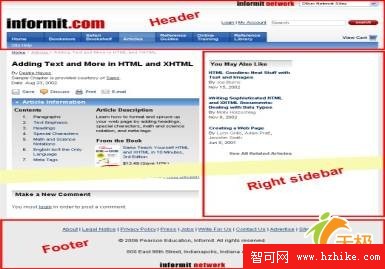
圖1一篇Informit文章的頁面結構
圖1一篇Informit文章的頁面結構
你僅需要從可導航DIV元素中刪除內容並且插入一個空框,頁眉將會出現在這裡(為了簡短起見,我們將忽略把公司標識和版權信息嵌入到每一個頁面中的討論)。下面是相應的代碼:
<div id="header">
<div style="height: 100px; width: 100%"></div>
</div>
<div id="contentArticle">
<div id="firstCol">
... article content ....
</div>
<div id="secondCol" ></div>
</div>
<div id="footer"></div>
<div id="header">
<div style="height: 100px; width: 100%"></div>
</div>
<div id="contentArticle">
<div id="firstCol">
... article content ....
</div>
<div id="secondCol" ></div>
</div>
<div id="footer"></div>
注意
如果你的web頁面使用表格來實現所希望的頁面布局,那麼請不要把表格單元格重用作占位符;而把DIV元素放到表格單元格內比較好一些。
已經被從web頁面中刪除的可導航的元素必須被重新創建為獨立的頁面。你應該使用靜態Html文件來表達靜態內容(這將允許緩沖內容,不管你使用什麼樣的web服務器)和在加載它們的web頁面上創建顯示基於動態元素的服務器端腳本。對於Informit來說,每一個web頁面都有唯一一個文章標識符(在URL中的"p="參數);因此,你需要創建一個能夠接受文章標識符並創建右邊的欄目的服務器端腳本。在大多數情況中,你可以重用創建嵌入的可導航元素的服務器端代碼。
在重新設計這些web頁面後,接下來,你就可以實現本方案中的AJax部分了。與通常一樣,你可以使用嵌入式框架(IFRAME元素)工作,也可以選用一個XMLHttpRequest對象。
三、 嵌入式框架
如果你關心浏覽器兼容性的話,你應該使用嵌入式框架。一些老式的浏覽器支持IFRAME元素,但不支持XMLHttpRequest對象。當然,使用這種方式還有如下一些理由:
· 被加載到一個IFRAME中的內容在裝載的過程中被顯示於浏覽器中,這向終端用戶顯示一個可視化進程。
· 頁面緩沖總是使用加載到一個IFRAME中的內容工作。一些版本的Opera還不能較好地使用XMLHttpRequest對象處理經緩沖的響應。
為此,我們可以把一個空IFRAME插入到每一個DIV容器中,並且在每一個IFRAME後添加一個簡短的JavaScript語句,如下所示:
<div id="header">
<div style="height: 100px; width: 100%"></div>
<iframe id="header_iframe" style="height: 0px;"></iframe>
<script>loadIframe("header","/navigation/header.Html")</script>
</div>
<div id="header">
<div style="height: 100px; width: 100%"></div>
<iframe id="header_iframe" style="height: 0px;"></iframe>
<script>loadIframe("header","/navigation/header.Html")</script>
</div>
IFRAME的id應該等於以_iframe為後綴的占位符的id。loadIframe函數使用了兩個參數:占位符的id和要加載到其中的URL。
技巧
如果你想在下載過程中使得IFRAME內容可見,那麼你應該使用一個適當大小的IFRAME元素來替換在占位符內的空的DIV框。然而,如果你想使IFRAME保持不可見,那麼你應該使用style屬性來把它的高度設置為0以克服一些浏覽器中的錯誤。
啟動裝載過程的loadIframe函數是很簡單的:
function loadIframe(id,url) {
try {
var iframeObj = document.getElementById(id+"_iframe");
iframeObj.src = url ;
} catch (err) {
alert("cannot load "+url+" into "+id) ;
}
}
function loadIframe(id,url) {
try {
var iframeObj = document.getElementById(id+"_iframe");
iframeObj.src = url ;
} catch (err) {
alert("cannot load "+url+" into "+id) ;
}
}
注意
本文中所有示例代碼都假定,浏覽器兼容文檔對象模型(DOM)。
然而,還沒有一種機制來通知請求頁面所希望的內容已經被加載到占位符IFRAME中。因此,被裝載的內容必須通知父頁面(經由一個JavaScript調用)可以使用該內容了。實現這一操作的最好時機是,在頁面加載完成以後。因此,在IFRAME內容中的BODY標志應該包含一個onLoad事件:
<body style="margin: 0px 0px;
padding: 0px 0px">
<body style="margin: 0px 0px;
padding: 0px 0px">
技巧
加載到IFRAME中的內容的body部分應該總是有零邊距和填充空白;否則,當把它集成到父頁面中時,它將會輕微地遷移。
在IFRAME的上下文中執行的contentLoaded函數將提取body部分相應的Html內容並且把它傳遞到一個在父頁面上下文中執行的函數,此函數將使用它來填充相應的占位符:
contentLoaded在IFRAME上下文的上下文中執行:
function contentLoaded(parentID) {
var myContent = document.body.innerHtml ;
parent.copyContent(parentID,myContent);
}
function contentLoaded(parentID) {
var myContent = document.body.innerHtml ;
parent.copyContent(parentID,myContent);
}
copyContent在父web頁面的上下文中執行:
function copyContent(id,content) {
try {
var placeholder = document.getElementById(id) ;
placeholder.innerHtml = content;
} catch (err) {
alert("Cannot copy Html content into "+id);
}
}
function copyContent(id,content) {
try {
var placeholder = document.getElementById(id) ;
placeholder.innerHtml = content;
} catch (err) {
alert("Cannot copy Html content into "+id);
}
}
現在,細心的讀者應該感到疑惑,為什麼這麼復雜?在IFRAME元素中加載導航元素不是更簡單一些嗎?事實證明,對於此方法還要加一些防止誤解的說明為好:
· IFRAME具有固定的高度和寬度。如果內容彼此超出,則內容將被剪掉或者IFRAME要加上滾動條。然而,被復制到一個在父頁面中的DIV元素中的Html標記其大小卻總是保持自動調整大小。
· 當在一個IFRAME中時,在導航內容中的鏈接(一個元素)將裝載IFRAME中的新頁面,除非你把target="_parent"添加到每一個鏈接之後。
· 依附到導航元素的JavaScript事件處理器將在IFRAME的上下文中工作(如果還保留這個上下文的話)。如果你把導航內容移動主頁面上,那麼事件處理器能夠存取在主頁面中定義的函數和變量。
四、 使用XMLHttpRequest
如果你的用戶主要使用Internet Explorer的較新版本或基於Gecko的浏覽器(Mozilla,Firefox,Netscape 7),那麼你可以決定使用XMLHttpRequest對象來把其它內容下載到你的web頁面中。第一步非常類似於前面描述的方式。對於每一個占位符,你需要一個JavaScript函數調用來啟動加載過程:
<div id="header">
<div style="height: 100px; width: 100%"></div>
<script>loadContent("header","/navigation/header.Html")</script>
</div>
<div id="header">
<div style="height: 100px; width: 100%"></div>
<script>loadContent("header","/navigation/header.Html")</script>
</div>
然而,loadContent函數是根本不同的:它創建了一個新的XMLHttpRequest對象,然後把一個事件處理器指派給它,並且異步啟動裝載過程:
function loadContent(id,url) {
try {
var rq = new XMLHttpRequest() ;
rq.open("GET", url, true);
rq.onreadystatechange = function() { contentLoaded(rq,url,id) }
rq.send(null);
} catch (err) {
alert("cannot load "+url+" into "+id) ;
}
}
function loadContent(id,url) {
try {
var rq = new XMLHttpRequest() ;
rq.open("GET", url, true);
rq.onreadystatechange = function() { contentLoaded(rq,url,id) }
rq.send(null);
} catch (err) {
alert("cannot load "+url+" into "+id) ;
}
}
注意
每一種主流浏覽器家族都以一種不同的方式實現了XMLHttpRequest對象。處理這種兼容性問題的最容易的方法是,使用一個包裝器庫,例如Sarissa。我們在本文中示例中就使用了這種庫。
回調函數contentLoaded負責檢查XMLHttpRequest對象是否已經准備好及完成狀態(如果請求已完成的話),並且從響應中提取HTML標記。提取HTML代碼(除非你使用XHtml,這種情況下,你可以使用XMLDOM接口)的最容易的方法是,使用字符串處理函數來查找<body>和</body>標志之間的文本:
function contentLoaded(rq,url,id) {
try {
if (rq.readyState != 4) { return; }
if (rq.status != 200) { alert("failed to load "+url); return; }
var txt = rq.responseText ;
//查找<body>標記的開始位置
var startBodyTag = txt.indexOf("<body")
//查找<body>標記的結束,跳過任何屬性
var endOfStartTag = txt.indexOf(">",startBodyTag+1)
//查找</body>標記
var endBodyTag = txt.indexOf("</body")
if (endBodyTag == -1) { endBodyTag = txt.length ; }
//提取實際內容
var bodyContent = txt.substring(endOfStartTag+1,endBodyTag)
if (bodyContent) {
var placeholder = document.getElementById(id) ;
placeholder.innerHtml = bodyContent;
}
} catch (err) {
alert("cannot load "+url+" into "+id) ;
}
}
function contentLoaded(rq,url,id) {
try {
if (rq.readyState != 4) { return; }
if (rq.status != 200) { alert("failed to load "+url); return; }
var txt = rq.responseText ;
//查找<body>標記的開始位置
var startBodyTag = txt.indexOf("<body")
//查找<body>標記的結束,跳過任何屬性
var endOfStartTag = txt.indexOf(">",startBodyTag+1)
//查找</body>標記
var endBodyTag = txt.indexOf("</body")
if (endBodyTag == -1) { endBodyTag = txt.length ; }
//提取實際內容
var bodyContent = txt.substring(endOfStartTag+1,endBodyTag)
if (bodyContent) {
var placeholder = document.getElementById(id) ;
placeholder.innerHtml = bodyContent;
}
} catch (err) {
alert("cannot load "+url+" into "+id) ;
}
}
與前面描述的基於IFRAME的方法相比,使用XMLHttpRequest對象具有下列好處:
· 代碼更干淨,並且不依賴於頁面的上下文切換。
· XMLHttpRequest對象使你能夠檢測和處理錯誤(通過它的readyState和status屬性)。而使用IFRAME加載內容時,如果出現錯誤,則只能顯示非常粗略的錯誤提示,這主要是因為缺乏對回調函數的調用。
· 你能夠實現內容元素的平行裝載(如在這一節中顯示的)或順序化裝載請求以最小化帶寬利用。
五、 小結
在本文中,你學習了怎樣實現把你的web頁面內容與包圍該內容的可導航元素分離開來。分離導致更為集中地描述搜索引擎要搜索的頁面內容,並且也減少了用戶使用低速互聯網存取的加載時間(既然是在可導航元素被下載之前把實際內容顯示給用戶)。
當重新設計你的web頁面來利用這種方案時,切記,一些基本格式的導航必須保留在頁面上以便允許搜索引擎和決定禁止使用JavaScript的用戶在你的網站的頁面之間進行導航。
你可以使用嵌入式框架(IFRAME)或使用在最現代浏覽器中實現的XmlHttpRequest對象來實現可導航元素的延遲裝載。IFRAME方法能夠為較老式的浏覽器所支持;因此,它可能是你要考慮使用的方法-如果你非常關心向後兼容問題的話。另一方面,XMLHttpRequest對象的使用使你能夠更為緊密地控制裝載過程並能夠檢測和處理下載錯誤。