目前,在互聯網上廣泛存在、應用的樹型結構一般分為兩種:靜態和動態結構。靜態結構存在最多、實現簡單,但是靜態導致不能改變樹的結構和內容,無法反映樹的節點信息的變化;而實現相對復雜的動態構造樹,雖然可以動態增加、刪除、更新節點信息,但是大部分不能直接拖放節點來改變樹的結構以及節點間的次序,並且反復刷新整個頁面,給用戶維護帶來了許多不便。本文提出了一種基於AJax(Asynchronous Javascript and XML)通用的、動態加載節點的解決方案。實現上采用J2EE多層架構,樹節點的描述信息采用數據庫存儲,以可擴展標記語言(eXtensible Markup Language,簡稱XML)展現給JavaScript解析,支持無刷新地增加、刪除、更新節點信息,以及拖放節點來改變樹的結構和節點間的次序。文中第1部分簡要介紹了AJax技術;第2部分詳細介紹了該方案的技術實現過程;第3部分分析了該方案的效率。
1、AJax簡介
Ajax概念的最早提出者Jesse James Garrett認為:AJax並不是一門新的語言或技術,它實際上是幾項技術按一定的方式組合在共同的協作中發揮各自的作用,它包括:
·使用擴展超媒體標記語言(eXtended Hypertext Markup Language,簡稱XHtml)和級聯樣式單(Cascading Style Sheet,簡稱CSS)標准化呈現;
·使用文檔對象模型(Document Object Model,簡稱DOM)實現動態顯示和交互;
·使用可擴展標記語言(eXtensible Markup Language,簡稱XML)和可擴展樣式表轉換(eXtensible Stylesheet Language Transformation,簡稱XSLT)進行數據交換與處理;
·使用XMLHTTP組件XMLHttpRequest對象進行異步數據讀取;
·最後用JavaScript綁定和處理所有數據。
Ajax的工作原理如圖1所示,它相當於在用戶和服務器之間加了一個中間層,使用戶操作與服務器響應異步化。並不是所有的用戶請求都提交給服務器,像—些數據驗證和數據處理等都交給Ajax引擎處理,只有確定需要從服務器讀取新數據時再由AJax引擎代為向服務器提交請求。這樣就把一些服務器負擔的工作轉嫁到客戶端,利用客戶端閒置的處理能力來處理,減輕服務器和帶寬的負擔,從而達到節約ISP的空間及帶寬租用成本的目的。
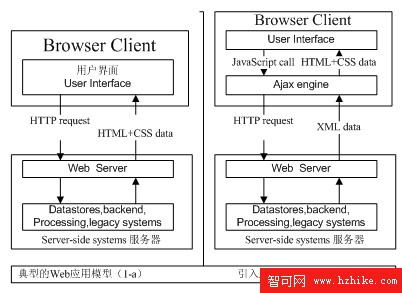
圖 1 未使用Ajax(a)和使用AJax(b)的web應用比較
2、總體設計方案
傳統的服務器程序采用Model 1開發模型,通常將業務邏輯、服務器端處理過程和Html代碼集中在一起表示,快速完成應用開發。Model 1 在小規模應用開發時優勢明顯,但是應用實現一般是基於過程的,一組服務器頁面實現一個流程,如果流程改動將導致多個地方修改,非常不利於應用的擴展和更新。此外業務邏輯和表示邏輯混合在服務器頁面中,耦合緊密,無法模塊化,導致代碼無法復用。
Model 2則解決了這些問題,它是面向對象的MVC模式(Model-VIEw-Controller,模型-視圖-控制器)在web開發中的應用,Model表示應用的業務邏輯,VIEw是應用的表示層頁面,Controller是提供應用的處理過程控制。通過這種MVC設計模式把應用邏輯,處理過程和顯示邏輯劃分成不同的組件、模塊實現,組件間可以進行交互和重用。
本方案是采用J2EE的多層架構,設計時結合Struts框架將表示層、業務邏輯層和數據層劃分成不同的模塊。表示層專注於樹的外觀顯示,業務邏輯層為服務器端處理程序,處理樹的生成、變化,為減少耦合性,該程序全部模塊化實現,不在表示頁面嵌入服務器程序;模型層是數據的存儲和表示。下面分別介紹各層實現。
2.1 表示層實現
類似Windows資源管理器的文件夾模式,節點的圖片樣式如表1所示。對於每個節點的DHtml 代碼,需要包含節點的位置、前導圖片、樣式、針對該節點的其他操作等。同時為了節點顯示的連貫性,還需一些前導圖片。
表1 樹節點的前的圖片樣式表
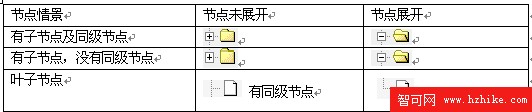
對於樹的非葉子節點,圖片和節點信息等,采用一個DIV ( division) 容器包含。DIV 等容器是DHtml 的基礎,使用它可以通過腳本程序對其屬性進行操作,如設置其style 樣式的display 屬性來控制子節點的展開和隱藏。節點的位置、前導圖片、樣式、針對該節點的其他的操作等都放入容器中,例:
< DIV id =mParentID>
< IMG align = center border = 0 onclick =″nodeExpand (‘leafid’)″ name = m1Tree src =′Tplus.gif′>
< IMG align = center border = 0 name = m1Folder src =′folderClosed. gif′> 計算機學院 </DIV>
葉子節點無需容器直接輸出即可。
當點擊某節點前的“ + ”、“ - ”圖片時通過DIV 的style 樣式的display 屬性控制子節點的展開和隱藏。display:“none”(隱藏,不可見),display:“block”(顯示) 。相關JavaScript 代碼如下:
if (expandChild.style.display = =″none″){
// 當前為隱藏狀態,執行展開動作
this.Loading(parentObject);//判斷該分支的數據是否已經加載
expandChild.style.display =″block″;
if (para2 = =″last″)
parentObject.src =″Lminus. gif″; // 最後一個節點
else
parentObject.src = ″Tminus. gif″; // 顯示┠
expandFolder.src = ″folderOpen. gif″;
}else {
// 將當前節點的子節點全部隱藏
expandChild.style.display = ″none″;
if (para2 = = ″last″)
parentObject.src = ″Lplus. gif″;
else
parentObject.src = ″Tplus. gif″;
expandFolder.src = ″folderClosed. gif″;
}
2.2 樹型表結構設計
我們以數據庫為載體記錄節點的變化,樹型表結構至少要有以下字段:節點的編號(CLASSID) ,對節點的描述(ClassName),父節點的編號(ParentId),這些是構建樹結構所必須的信息。同時引入節點的類別代碼(ClassCode),節點的級別(ClassLevel),是否葉子節點 (Terminated)等輔助字段,記錄節點次序,實體關系圖如圖3所示。
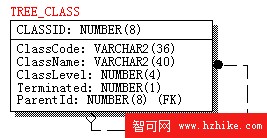
圖 3 樹型表結構示意圖
樹遍歷的時間復雜度是O( n ),但是將樹信息存放到數據庫後,就不能按傳統的方式遍歷樹,必須使用SQL 語句訪問數據庫表的內容,而一次性取的數據量越多,消耗的資源也越多,用戶等待的時間就越長。如果將無序的數據從數據庫中讀出,在服務器端,必須將排序後的樹送到客戶端顯示。因此,最好從數據庫讀出已排好序的樹。
我們知道,字符串排序是按照字典序形式。結合SQL 語句的特點和樹結構特點,數據庫表中,節點的類別代碼采用多級字符串形式,如AAABBBCCC,從樹根節點開始,每向下一級字符串就增加一級,並且子節點類別代碼以父節點類別代碼開始,再開始本級的類別代碼。同級的節點按照生成的順序編號,如節點類別代碼為AAA 的下一級孩子類別代碼為AAAAAA,AAAAAB 等,AAAAAB 的孩子節點為AAAAABAAA、AAAAABAAB等。每一級編號字符的寬度與實際的應用關聯,如AAA~ZZZ 一級則有263 個節點,如果不夠用再增加一個字符用於編碼。該巧妙的編號方式。使得在執行SQL 語句select * from tree_class order by classcode 後,一次獲得完整的先序樹。
2.3 業務邏輯層設計
2.3.1 動態加載技術
如果一次性獲取完整的先序樹,構造成xml提供給Javascript解析,數據量越大,消耗的資源越多,客戶端響應延遲時間就越長,因此對於大數據量的樹,采用動態加載方式,即每次單擊“+”圖片時,判斷是否已加載子節點數據,如果未加載則通過AJax的XMLHTTP組件XMLHTTPRequest對象異步發送請求,連接服務器執行SQL 語句“select * from tree_class where parent = ?order by classcode ”獲取節點數據。相關JavaScript 代碼如下:
/*判斷是否已經加載數據,未加載則訪問服務器加載數據*/
dHtmlTree.prototype.Loading=function(pObject){
if(((pObject.XMLload==0)&&(this.XMLsource))&&(!this.XMLloading)){
pObject.XMLload=1;
this.loadXML(this.XMLsource+getUrlSymbol(this.XMLsource)+"id="+escape(pObject.id));
}
}
dtmlXMLObject.prototype.loadXML=function(url){//加載數據
try {
this.xmlDoc = new XMLHttpRequest();
/*通過GET方法異步連接到 url 加載數據*/
this.XMLDoc.open("GET", url,true);//true:異步;false:同步
this.XMLDoc.send(null);
} catch(e){
this.xmlDoc = new ActiveXObject("Microsoft.XMLHTTP");//使用IE
this.XMLDoc.open("GET", url,true);//true:異步;false:同步
this.XMLDoc.send(null);
}
return this.xmlDoc.responseXML;
}
每次只取同一個父節點ParentId的子節點序列,按XML格式封裝成樹的文檔結構,例如:
<tree id="0">
<leaf child=”1" name="國防科技大學" id="1" im0="leaf.gif" im1="folderOpen.gif" im2=" folderClosed.gif"/>
</tree>
提供給JavaScript的DHtmlTreeObject.prototype.insertItem()解析並組織好Html輸出節點;其中child:1表示有子節點,0表示沒有子節點;im0表示沒有子節點時的圖標;im1表示有子節點並且打開節點時的圖標;im2表示有子節點並且關閉時的圖標;所以還可以在構造XML時自定義圖標。
2.3.2 樹型結構的構造
從數據庫中返回的是有序的先序樹,而XML是完整的樹型結構文檔,所以將樹型數據構造成預定義的XML格式,只需從根節點開始,遍歷一遍樹,即可將樹全部生成。相關JavaScript代碼如下:
/*動態加載樹的構造方法*/
dtmlXMLObject.prototype.constructTree=function(){
//采用動態加載時獲取的XML數據,解析樹型數據
var node=this.XMLLoader.getXMLTopNode("tree");
var parentId=node.getAttribute("id");
for(var i=0;i<node.childNodes.length;i++) { //逐個解析XML文件的leaf節點
if((node.childNodes[i].nodeType==1)&&(node.childNodes[i].tagName == "leaf")){
var name=node.childNodes[i].getAttribute("text");
…………
var temp=dHtmlObject.a0Find(parentId);//獲取父節點對象
temp.XMLload=1;//已加載
//構造Html輸出節點
dHtmlObject.insertItem(parentId,cId,name,im0,im1,im2,chd);
dHtmlObject.addDragger = this;//設置可拖放的對象
};
}
2.3.3 樹型結構的維護
在維護樹型結構表時,刪除節點較為簡單,SQL 語句為: "delete from tree_class where classcode like′"+ classcode +"%′",即可將其節點和孩子一並刪除;增加節點時,分為前插、後插、和插入子節點三種情況,前兩種情況需要更新遞歸更新類別代碼,後者只需找到父節點的孩子的最大類別代碼加1 後,作為增加節點的類別代碼;通過拖放來改變樹的結構時,只需將拖動節點的parentId更新為目標節點的Classid即可,對應的SQL語句為:"update tree_class set parentId = "+ classidTo+" where classid = "+ classidFrom。
3、效率分析
對於樹的存儲一般有兩種形式:二維表和鏈表,遍歷方式一般也有深度遍歷和廣度遍歷兩種方式,遍歷的時間復雜度都是O( n )。用二維表存儲時,在內存中用數組的下標能准確定位節點的父節點、兄弟節點所在的數組下標。數據庫中節點的定位也是准確的,但是將節點信息從數據庫中讀到內存中時,如果無法通過內存數組下標定位節點信息,那麼就必須遍歷一遍尋找一個節點,n 個節點中尋找一個節點的時間是O(n/2),n 個節點排序的時間復雜度將是O( n 2/2),這也是一般實現的B/S 模式的樹結構效率低下的原因。本方案采用字典序編號方案,使得從數據庫中取得的樹是已經排序的,直接遍歷生成客戶頁面程序,時間復雜度為O( n )。
4、結 論
本文討論了基於AJax的動態樹型結構的實現方案,支持無刷新動態維護樹的節點信息,支持拖放節點改變樹的節點結構以及次序;同時采用數據庫存儲節點信息,保證了該方案有一定的通用性,此外結合XML描述樹的節點信息,使得任何按本方案預定的XML文檔描述的信息都可以通過樹來展現。本方案已經應用在我校的數字迎新系統以及老百姓大藥房信息系統中。
- 上一頁:AJAX與數據庫技術
- 下一頁:AJAX技術介紹(什麼是AJAX?)