混亂的URL編碼
編輯:關於網頁技巧
URL全稱Uniform Resource Locator,直譯為“統一資源定位符”,也就是網頁地址,是互聯網上任意角落都可以訪問到的,言外之意是說,URL不受國別、種族、語言、編碼差異的約束,是編碼無關的。然而我們常常在浏覽器中敲入諸如“http://url/中文”的url,也能正確訪問,既然url中包含中文,那麼如何讓其他國家那些沒有中文編碼的計算機上也能訪問到相同的網址呢?
RFC 1738中對URL有明確規定,URL必須由英文字母、數字、和某些標點符號組成,不能使用其他文字,因此所有包含中文的URL都應當是非法的!其實,浏覽器自作聰明的為我們做了很多人性化的hack,比如,浏覽器會對地址欄中填入的url進行先編碼再使用,因此,不論怎樣,一個正確封裝的http包中的URI字段一定不會出現中文字符。也就是說,實際發生作用的url也一定如RFC 1738中所言,非ascII碼要先轉換成ascII碼序列,但RFC 1738沒有規定具體的編碼方法,而是交給應用程序(浏覽器)和web程序作者自己決定。這導致“URL編碼”成為了一個混亂的領域。也會導致一些奇怪的現象發生。
我們分別在firefox和ie用baidu和google搜索“淘寶”。
在firefox中百度“淘寶”,出現:
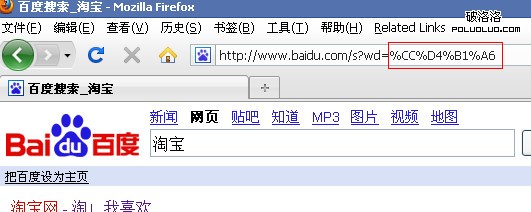
實際發生請求的url為:
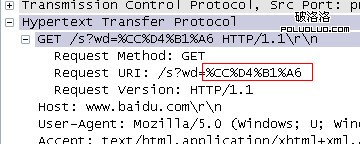
同地址欄中顯示是一致的,搜索結果也正確。在地址欄中直接輸入“http://www.baidu.com/s?wd=淘寶”也是如此,在firefox中google“淘寶”:
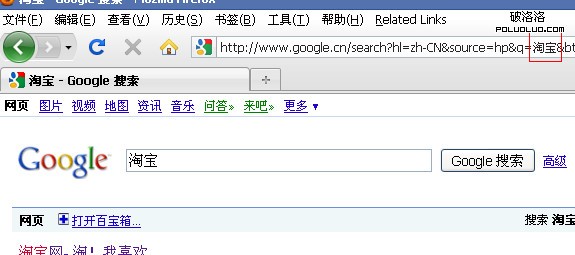
實際發生請求的url為:
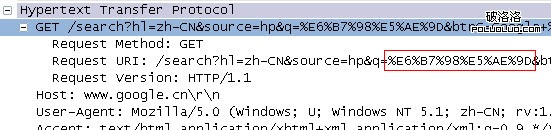
可以看到,實際發生請求的url和地址欄顯示的url不一致,搜索結果正確。這時,重新請求地址欄的“url”(不是刷新),地址欄顯示為:

實際發生的請求為:
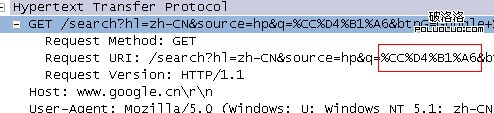
這時,地址欄和實際發生的請求是一致的,搜索結果正確。進一步分析之前,先看看js裡的兩個運算
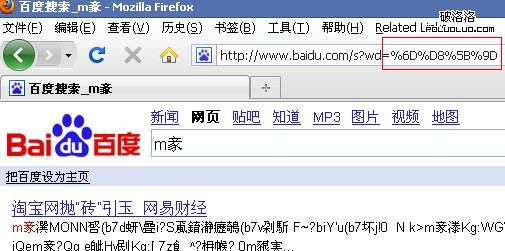
我們知道escape()是計算unicode編碼,傳說中正統的URL編碼encodeURI()則是進行utf-8編碼,(簡單講,unicode編碼是純粹的編碼方式,utf-8是unicode編碼的一種實現,即將二進制unicode編碼再編碼,以一種比較節約空間的方式對unicode全集進行二次編碼)。escape()的結果是將每個unicode字符以%u分割,encodeURI是每個字節以%分割,也就是說,“淘”和“寶”的unicode編碼分別是“6DD8”和“5B9D”,他們的utf-8編碼分別是“E6 B7 98”和“E5 AE 9D”,此外,他們的gbk編碼分別為“CC D4”和“B1 A6”。
初步得到結論一:在firefox中的百度搜索,通過form提交的中文轉換為gbk編碼,參與http包的封裝。在ff中google搜索,通過form提交的中文轉換為utf-8編碼,但顯示在地址欄中的url是其中文映像(如果這時將地址欄復制下來,復制的實際是轉碼後的url,無法復制url中的中文字符)。如果直接在ff地址欄中輸入中文url,這時,url裡的中文字符一律進行gbk編碼,不管百度還是google都是如此。
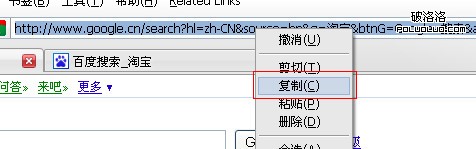
復制不了裡面的中文
如此看來,firefox默認處理url裡的中文,都是通過gbk編碼進行編碼的,這裡和網頁編碼無關(浏覽器無法檢測將要被訪問的網頁編碼)。
那麼,百度和google對unicode編碼和utf-8編碼的支持情況如何呢?
“淘寶”的unicode編碼為“%6D%D8%5B%9D”,在ff中訪問“http://www.baidu.com/s?wd=%6D%D8%5B%9D”
搜索到亂碼。“淘寶”的utf-8編碼為(所謂正宗的“URL”編碼)“%E6%B7%98%E5%AE%9D”,在ff中訪問“http://www.baidu.com/s?wd=%E6%B7%98%E5%AE%9D”,得到,
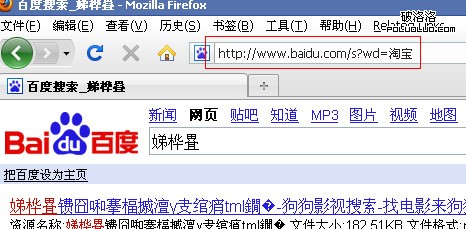
也是亂碼。
再來看google能否解析utf-8編碼,在ff中訪問“http://www.google.cn/search?q=%E6%B7%98%E5%AE%9D”,得到,
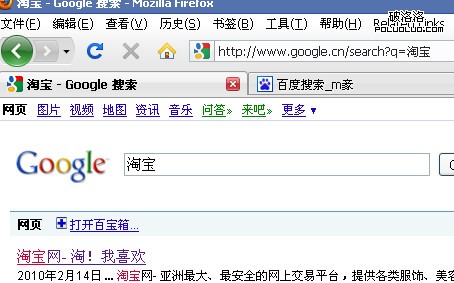
結果正確,google可以正確解析utf-8編碼。再看google能否解析unicode編碼,在ff中訪問“http://www.google.cn/search?q=%6D%D8%5B%9D”,得到:
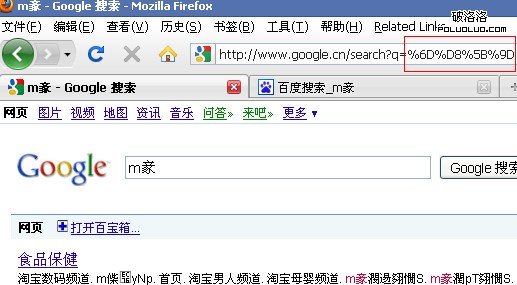
是亂碼。
初步得到結論二,所謂正統的URL編碼encodeURI並不是萬能的,要看每個網站的實現,百度搜索就不支持這個所謂正統,而是一律采用gbk系的編碼作為自己的URL編碼。google支持“正統URL編碼”,也支持gbk系的編碼,更健壯一些。
再來看IE中的情況,在ie中在百度和google中通過form搜索“淘寶”結果和ff中一致,但直接在地址欄中輸入中文url就有些奇怪了,在ie中訪問“http://www.baidu.com/s?wd=淘寶”,得到,
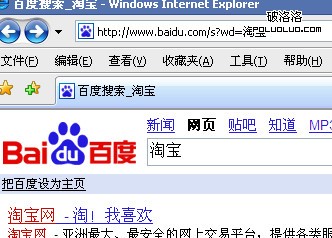
結果當然正確,實際發生的請求為
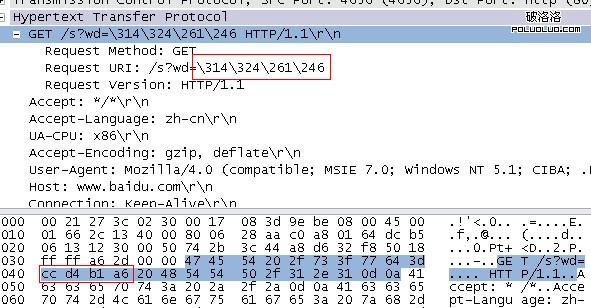
這裡可以看到,ie發起的http請求甚至沒有經過任何編碼,硬生生的將“淘寶”當作原始gbk字符,這樣,其他語言編碼的操作系統就無法識別這個url,這裡的“\314\324\261\246”是一種我也不知道是什麼東西的編碼,甚至連wireshark都不知道,因為“http://www.baidu.com/s?wd=\314\324\261\246”明顯是一個錯誤的請求。
此外,unicode編碼和utf-8編碼後的url在ie下的表現和ff中一致。
由此,可得到結論:
1,RFC 1738文檔很粗糙,導致了url編碼標准缺失。實際url編碼標准和操作系統、浏覽器以及web應用有關;
2,ff對非ascII碼的url進行編碼,編碼方式和操作系統默認編碼一致
3,google支持“正統的URL編碼”(即utf-8 URL編碼:utf-8字節中間加上%),百度不支持
4,IE不對非ascII碼的url進行編碼,直接根據操作系統默認編碼發送url請求,換句話說,ie甚至不遵循RFC 1738,或者說ie對URL的轉碼實現有bug。
5,ff在地址欄顯示的url進行了hack,但hack的有bug,開發時要注意。
基於此,我們在web開發過程中要做到:
1,要單獨處理編碼問題,建議采用統一的URL編碼,不論是gbk還是unicode還是URI(utf-8),必須要統一,鑒於大多數人稀裡糊塗的認為URI是正宗的URL編碼,因此建議還是在前後端都做URI編碼和解碼。
2,明智選擇web app的編碼,utf-8為最佳,gbk為最次。
3,編碼問題要調試浏覽器兼容性。
以上~
附:
中日韓unicode字符集
gbk字符集
小編推薦
熱門推薦